データ収集を自動化するAI:特許価値評価の最初の一歩を加速
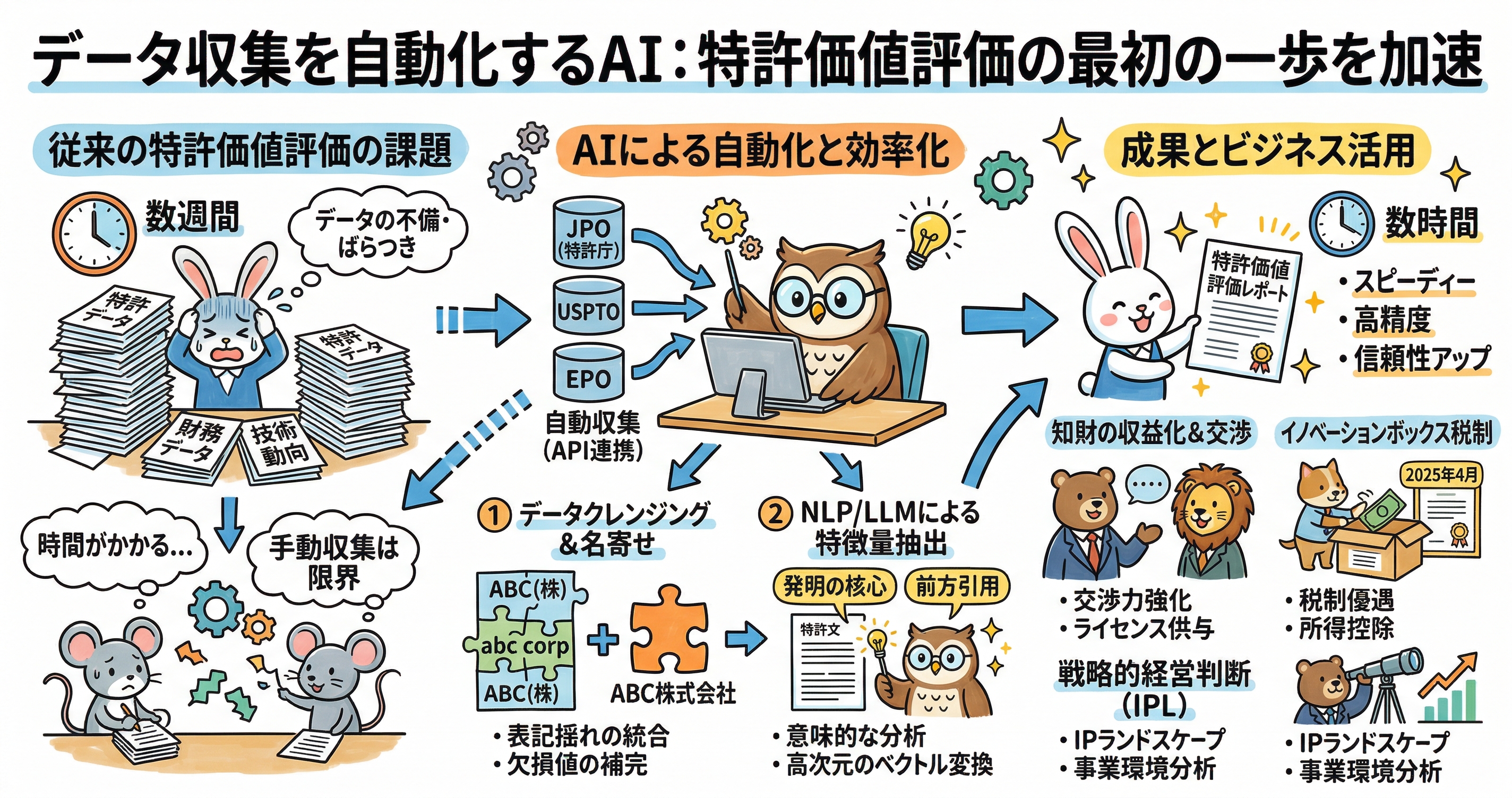
株式会社IPリッチのライセンス担当です。本記事では、知的財産管理の要となる「特許価値評価」において、AIがいかにしてデータ収集と前処理の工程を革新し、評価の精度と速度を劇的に向上させているかについて、専門的な見地から詳述いたします。従来、特許評価の土台となる財務データやライセンス情報、技術動向の収集には膨大な時間と専門知識が必要とされてきました。しかし、現代の機械学習モデルや大規模言語モデルの台頭により、これらのプロセスはリアルタイムでの自動取得と高度な整理が可能となり、数週間を要していた作業がわずか数時間へと短縮されつつあります。本稿では、AIによるデータ収集・クレンジングの具体的なメカニズムを解き明かし、それが知財戦略にどのような変革をもたらすのかを解説します。
近年のビジネス環境において、企業が保有する知的財産を単なる防衛手段としてではなく、ライセンス供与や売却を通じて直接的な利益を生む資産として活用する「知財の収益化」というテーマは、経営戦略の最優先課題となっています。自社の技術が市場でどのような立ち位置にあり、いくらの価値を持つのかを正確に把握することは、収益化に向けた戦略立案の第一歩です。精度の高い価値評価は、投資家への説明責任を果たすだけでなく、M&Aや技術移転における交渉力を強化する不可欠な要素となります。弊社が運営する特許売買・ライセンスプラットフォーム「PatentRevenue」では、こうした知財の収益化を加速させるため、特許権の売買やライセンスを希望される方々に向けて、無料での会員登録を推奨しております。最新の市場データに基づいたマッチングや取引を円滑に進めるための環境を整えておりますので、ぜひ「PatentRevenue」( https://patent-revenue.iprich.jp/#licence )をご活用いただき、貴社の知的財産の可能性を最大限に引き出してください。
Patent Value Analyzer | 特許収益化の可能性を無料評価
特許データの自動収集とAIによる効率化
知的財産の価値を金銭的に算定するプロセスは、対象となる特許が持つ技術的独創性、権利の法的安定性、そして市場における経済的寄与度の三要素を統合する極めて複雑な作業である。かつての評価手法では、評価人が個別に適していると判断した独自の手法を採用することが多く、統一された評価基準の確立が困難であった 。特に、評価の基礎となる情報の収集段階において、人手による網羅的な調査には限界があり、重要な先行技術や競合他社の動向、さらにはライセンスの成約事例といった非公開に近い情報の欠落が、評価結果のばらつきを生む主因となっていた 。
AI技術、特に高度なデータスクレイピング技術とAPI連携機能を備えた機械学習モデルの導入は、この情報収集のフェーズに劇的な変革をもたらした。最新のAIシステムは、特許庁が提供する膨大な公報データベースや、米国のUSPTO、欧州のEPOといった各国の知的財産機関、さらには企業のCRM(顧客関係管理)システムやERP(企業資源計画)とリアルタイムで同期することが可能である 。これにより、従来は断片的にしか入手できなかった法的ステータスや年金納付状況、引用関係の変遷、さらには権利移転の履歴といったデータを、瞬時に一つのデータセットとして統合できるようになった 。
特許文書は、厳格な法的形式と専門的な技術用語が組み合わさった特殊な構造を持つが、近年の自然言語処理(NLP)技術は、こうした複雑な文書から発明の主要な構成要素である請求項(クレーム)の範囲や、引用情報のネットワーク構造を自動で抽出する能力を有している 。AIによる自動化の最大の利点は、人間が数日かけて読み込む量を数秒で処理できる処理能力だけでなく、評価に必要な情報を「定量的」かつ「定性的」に同時取得できる点にある。例えば、特許の重要度を示す指標として広く用いられる「前方引用件数(Forward Citations)」についても、単なる数字としてではなく、どの技術分野のどの企業から引用されているかという文脈までを含めて自動収集・整理できるため、評価の解像度が飛躍的に高まるのである 。
機械学習を活用したデータクレンジングと名寄せの仕組み
収集された生データには、多くの場合、表記の揺れや不備、重複といった「ノイズ」が混入しており、これが分析の精度を著しく低下させる。特に、特許出願人の名称における表記揺れは深刻な課題である。同一企業であっても、日本語での「株式会社」の有無、英語表記のスペルミス、合併や分社化に伴う権利承継、あるいは略称の使用などにより、システム上では別の主体として認識されてしまうことが多々ある 。このようなデータの不備は、ポートフォリオ分析において特定の企業が保有する真の権利規模を見誤らせる原因となる。
AIによるデータクレンジングは、こうした課題を解決するために、単なる文字列の一致確認を超えた「名寄せ(Entity Resolution)」のアルゴリズムを実行する。まず、ルールベースの処理によって全角・半角の統一や空白の除去、法人格表記の正規化を行い、データの土台を整える 。その上で、ルールでは対応しきれない曖昧な表記や、未知の異常値の検出にAIが適用される。例えば、住所情報や特許の技術分類(IPC/CPC)の重なり、あるいは過去の権利移転のパターンを学習したAIは、異なる名称で登録されている出願人が実質的に同一の法人である可能性を確率的に算出し、高精度に統合することができる 。
さらに、AIは欠損値の特定と自動補完においても重要な役割を果たす。データベースにおいて一部の財務情報やライセンス料率が欠落している場合でも、AIは類似した技術特性を持つ他の特許データや、当該企業の過去の傾向から、統計的に妥当な値を推定して埋めることが可能である 。このようにして「クリーン」に整えられたデータは、機械学習モデルの学習効率を最大化させ、結果として評価プロセスの信頼性を底上げすることにつながる。データの正規化は、異なるスケールを持つ指標(例:引用件数と売上高)を統一的な尺度で比較可能にし、アルゴリズムの収束を早める効果も持っている 。
大規模言語モデルによる特許価値の精密評価と特徴量抽出
データが整理された後、次に行われるのが特許の質的側面を数値化する「特徴量抽出」である。従来の評価手法は、被引用数などの単純な書誌データに依存しがちであったが、これでは発明の本質的な革新性やビジネス上の優位性を十分に捉えきれない場合があった 。ここで、トランスフォーマー型の大規模言語モデル(LLM)をはじめとする深層学習技術が真価を発揮する。
LLMは、特許のテキストデータ全体を「埋め込み(Embedding)」と呼ばれる高次元のベクトル空間に変換することで、文脈上の意味を捉えたセマンティックな分析を実現する 。この手法により、キーワードが一致していなくても、技術的思想が類似している特許群を瞬時に特定できるようになる。例えば、IoT分野における特定の通信プロトコルに関する特許が、将来的にスマートシティやヘルスケアといった別分野でどれほどの波及効果を持つかを、セマンティックな類似度と過去のイノベーションの軌跡に基づいて予測することが可能である 。
AI特許そのものの価値に関する実証研究によれば、AI関連特許は非AI特許と比較して約9%の価値プレミアム(価値の底上げ)が付与されており、前方引用件数も26%高いことが示されている 。投資家は、AI技術が持つ知識の波及効果や幅広い商業化の可能性を高く評価しており、AIを用いてこれらの価値を定量化すること自体が、市場の信頼を獲得する手段となっている 。AIモデルは、過去数十年分の特許データと、それらがその後市場でどのような収益を生んだかという結果を学習することで、ターゲットとする特許が将来生み出し得るキャッシュフローを確率的に見積もる能力を備えている 。このように、AIによるマルチファクタ分析(多要因分析)は、発明者の技術力、特許の独創性、関連市場の成長率といった多角的な指標を組み合わせることで、従来の人間による評価を凌駕する説得力を持たせているのである 。
知財の収益化を支える市場動向と経済的評価
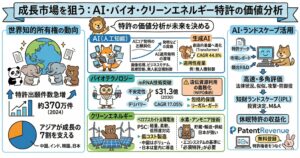
知財の収益化を取り巻く環境は、国内外で急速に整備が進んでいる。特許庁が発表した2024年版の報告書によれば、2023年の特許出願件数は30万件を超え、微増傾向にある 。特に出願全体の約4分の1を外国人が占めるなど、知財のグローバル化が進展しており、権利化までの期間短縮(平均13.8か月)といった行政側の努力も、知財の迅速な活用を後押ししている 。このような活発な市場環境において、世界の特許分析市場は2025年に12.6億ドルに達し、2034年には37.2億ドル規模にまで拡大すると予測されている 。
日本政府も、知財・無形資産を企業の持続的な価値創造の源泉と位置づけ、その投資と収益のつながりを可視化することを強く推奨している 。特に注目すべきは、2025年4月から本格的な運用が予定されている「イノベーションボックス税制(イノベーション拠点税制)」である 。この制度は、国内で行った研究開発から生じた特許権やAI関連ソフトウェアの著作権に基づく所得に対し、30%の所得控除を認めるというものである。これにより、企業は知財を「コスト」ではなく、将来の税負担を軽減しキャッシュフローを改善する「資産」としてより明確に認識するようになる。
この税制優遇措置を適切に受けるためには、対象となる特許がどのような研究開発から生まれ、どの程度のライセンス所得に寄与しているかを厳密に証明しなければならない。ここで、AIによるデータ収集と整理の仕組みが大きな役割を果たす。AIを活用して知財・無形資産の価値を可視化し、SX(サステナビリティ・トランスフォーメーション)やインパクト会計といった情報開示に組み込むことで、投資家からの信頼を獲得し、さらなる投資を呼び込むという好循環が形成されるのである 。また、コンテンツ産業においても、2033年までに海外展開規模を20兆円に引き上げるという野心的な目標が掲げられており、著作権管理や価値評価の自動化は、産業全体を支えるインフラとしての重要性を増している 。
未来の知財戦略におけるAI活用の展望と法的課題
AIが特許価値評価の精度を高めることは、企業の経営判断を高度化させる。旭化成のような大手企業では、IPランドスケープ(IPL)を駆使し、経営層や事業責任者に対して技術的な視点からの事業環境分析を提供している 。具体的には、自社と他社の特許が一体となって集合を形成している技術領域を精査し、両社のシナジー(相乗効果)を明確にすることで、M&Aや事業提携におけるベストオーナーの特定に役立てている 。このような高度な意思決定は、AIによってクレンジングされ、整理された膨大なデータがあって初めて実現するものである。
しかし、AIの活用が拡大する一方で、克服すべき課題も浮き彫りになっている。その一つが、AIモデルの判断に対する透明性と説明責任(エクスプレナンダ)の確保である。AIが算出した価値評価額が、どのような論理的ステップを経て導き出されたのかが不明確であれば、法的紛争や巨額の取引においてその結果を全面的に信頼することは難しい 。そのため、結果の根拠を人間が理解可能な形で提示する「説明可能なAI(XAI)」の研究が、特許評価の分野でも加速している。
また、AIによる自動化が進むことで、知財専門職に求められるスキルセットも変化している。単純なデータ収集や形式的な事務作業はAIに置き換わるため、人間にはAIが出力した結果を戦略的な文脈で解釈し、経営層に提言する能力や、複雑なライセンス交渉を遂行する高度な専門性がより一層求められるようになる 。さらに、生成AIによる特許草案の作成や、AIが自律的に先行技術を特定するプロセスにおいて、既存の著作権や特許権を侵害しないよう、技術・法・契約の三位一体となったガバナンス体制を構築することが、今後の知財エコシステムの再構築において不可欠な要素となるだろう 。
特許価値評価の自動化は、知的財産を「守りの資産」から「攻めの資本」へと変貌させるためのエンジンである。正確なデータ収集とクレンジングという堅実な一歩をAIが加速させることで、企業は変化の激しい市場環境においても、自社の技術が持つ真の価値を羅針盤として、確かな成長戦略を描くことが可能になるのである。
(この記事はAIを用いて作成しています。)
- 日本弁理士会 https://jpaa-patent.info/patent/viewPdf/3953
- 特許庁「特許行政年次報告書2024年版」 https://www.jpo.go.jp/resources/report/nenji/2024/index.html
- 特許庁「特許行政年次報告書2024年版のとりまとめ」 https://www.jpo.go.jp/resources/report/nenji/2024/matome.html
- 前田特許事務所「特許行政年次報告書2024年版発行」 https://maedapat.co.jp/reports/364/
- 旭化成株式会社「知的財産報告書2024」 https://www.asahi-kasei.com/jp/r_and_d/intellectual_asset_report/pdf/ip_report2024.pdf
- 特許庁「特許庁ステータスレポート2024」 https://www.jpo.go.jp/resources/report/statusreport/2024/document/index/all.pdf
- Shahzeb Akhtar, The Role of Artificial Intelligence in Enhancing Patent Lifecycle Management https://www.researchgate.net/publication/390207842_The_Role_of_Artificial_Intelligence_in_Enhancing_Patent_Lifecycle_Management
- Harvard Business School, The Value of AI Innovations https://www.hbs.edu/ris/download.aspx?name=24-069.pdf
- Arxiv, Deep Learning for Patent Analysis: A Survey https://arxiv.org/html/2403.04105v1
- Arxiv, AI-based Tools for Patent Analysis https://arxiv.org/html/2404.08668v2
- Scitepress, AI-driven Methodology for Patent Evaluation https://www.scitepress.org/Papers/2025/135197/135197.pdf
- Beerfroth, AI Data Cleansing for Business https://www.beerfroth.com/marketing-blog/ai-data-cleansing/
- Atstream, AI-based Data Cleansing and Entity Resolution https://note.com/atstream/n/na4971a88118f
- Geniee, Data Deduplication and Matching Logic https://geniee.co.jp/media/cdp/data-deduplication-matching-logic/
- Ricoh, AI for Work Column: Data Normalization https://promo.digital.ricoh.com/ai-for-work/column/detail009/
- Fortune Business Insights, Patent Analysis Market Size & Forecast https://www.fortunebusinessinsights.com/jp/%E7%89%B9%E8%A8%B1%E5%88%86%E6%9E%90%E5%B8%82%E5%A0%B4-102774
- 首相官邸 知的財産戦略本部「知的財産推進計画2024」 https://www.kantei.go.jp/jp/singi/titeki2/tyousakai/kousou/2025/dai1/siryou1.pdf
- リスクモンスター株式会社「AI企業データ名寄せサービス」 https://www.riskmonster.co.jp/service/ai-nayose/
- Hubspot, Deduplication with Generative AI https://blog.hubspot.jp/marketing/deduplication-ai
- Note, AI-driven Corporate Data Cleansing https://note.com/sn_osamu_araki/n/n4e7a4ca63b8f