生成AIのビジネス利活用とデータ・知財保護の最新法的実務
株式会社IPリッチのライセンス担当です。昨今、あらゆる産業分野において生成AI(人工知能)の導入が急速に進み、業務効率化や新規事業の創出など、企業のデジタルトランスフォーメーションが強力に推進されています。その一方で、AIの学習モデルの構築や、AIが生成したコンテンツの出力に伴うデータの利活用において、著作権をはじめとする知的財産権の保護や、個人のプライバシーに関する法的な枠組みの正しい理解がこれまで以上に重要となってきました。本記事の趣旨は、企業が生成AIを安全かつ効果的に導入・運用していくために不可欠となる著作権法や個人情報保護法の最新の法的解釈を整理し、実務におけるリスクマネジメントの明確な指針を提供することにあります。複雑化する法的課題を平易な言葉で紐解きながら、適切なデータ管理がビジネスの競争力向上にどうつながるのかを詳細に解説いたします。
こうしたAI時代の法的課題に対する適切なリスク管理は、単なる法令遵守という守りの姿勢にとどまらず、自社が保有するデータ資産の価値を最大化し、「知財の収益化」を実現するための極めて重要な基盤となります。データを戦略的な無形資産として捉え、法的に安全な環境でプロダクト化することは、新たなビジネスモデルの創出や強固な競争優位性の獲得に直結するからです。このように高度なデータガバナンスと知財戦略を両輪で推進するためには、法律とテクノロジーの双方に精通した専門知識を持つ優秀な人材の確保が企業の急務となっています。知財人材を採用し、知財の収益化を加速させたいと考える事業者様は、ぜひ求人情報を無料で登録できる「PatentRevenue」をご活用ください。求人登録はこちらのURL( https://patent-revenue.iprich.jp/recruite/ )から行えます。専門人材の採用を通じて、御社の知財戦略は次のステージへと飛躍するはずです。
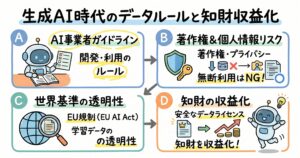
生成AIの学習段階における著作権法の適用と非享受目的の理解
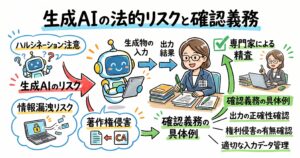
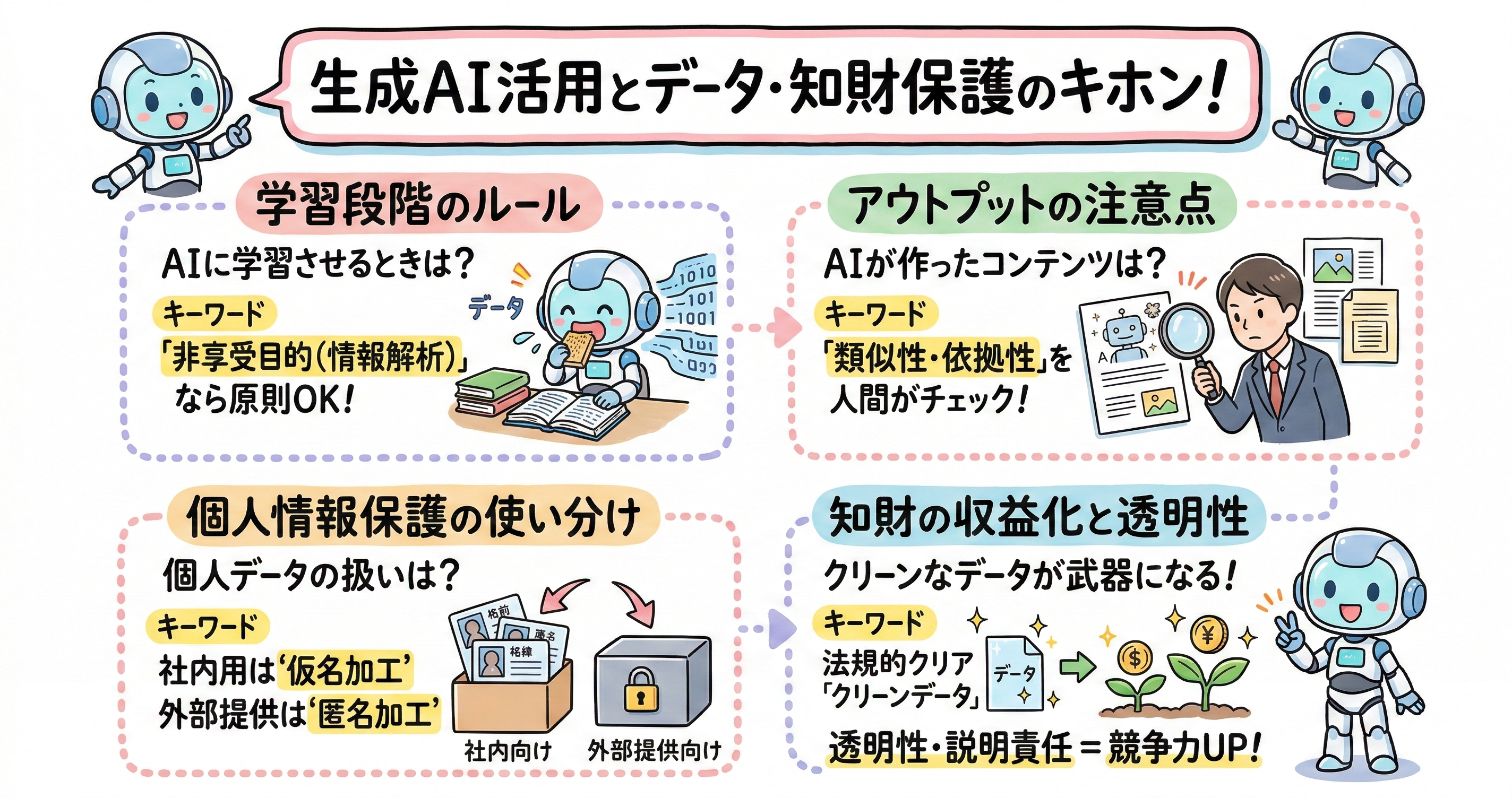
企業が生成AIをビジネスに活用する際、あるいは独自のデータを用いてAIモデルを開発・ファインチューニングする際、既存のデータや著作物をどのように取り扱うべきかが最初の大きな関門となります。この問題は、AIがデータを取り込む「学習段階(インプット)」と、結果を出力する「生成・利用段階(アウトプット)」の二つのフェーズに分けて整理することが法務実務上の基本です。まずは、学習段階における著作権法の解釈について深く掘り下げていきましょう。
日本の著作権法第30条の4は、世界的に見ても機械学習やデータ解析に柔軟な枠組みを提供している画期的な条文として知られています。この条文の核心は、著作物に表現された思想又は感情を自ら享受し、又は他人に享受させることを目的としない場合、すなわち「非享受目的」であるならば、原則として著作権者の許諾を得ることなく著作物をAIの学習用データとして利用できるという点にあります 。ここで極めて重要になるのが、「認識」と「享受」という二つの概念の明確な線引きです。
法的な解釈において、著作物の表現を「認識」するとは、人間が物事を知る働きとして、単にその著作物の表現がどのようなデータ構造や特徴を持っているのかを情報解析の対象として知るにとどまる状態を指します 。機械学習のプロセスは、大量の画像やテキストデータを読み込み、そこからパターンや規則性、パラメーターの重み付けを抽出する作業であり、まさにこの「認識」の範疇に収まります。一方、「享受」するとは、単なる認識にとどまらず、その著作物が持つ芸術性やメッセージ性を受け入れ、味わい、楽しむといった、より深い能動的かつ精神的な作用を伴うものと定義されています 。AIがデータを数学的なベクトルとして処理する行為は享受には当たらず、基本的には非享受目的に該当するため、適法に学習を行うことが可能とされています。
しかしながら、実務の現場では「AIに学習させる目的と、その出力結果を後で人間が楽しむという享受目的が併存しているのではないか」という疑問がしばしば呈されます。この「併存」論争について、最新の法的考察では、併存という概念を介在させる実益はないと整理されています 。なぜなら、著作権法第30条の4は「享受目的があるか否か」というゼロサムの判断基準を設けているからです。享受目的が少しでも認められるのであれば、それはもはや非享受目的とは言えず、同条の適用外となって原則通り著作権者の許諾が必要となります。非享受目的と享受目的が並列に存在するかのような議論は、法解釈の誤解を招く恐れがあるため、端的に享受目的の有無のみを検証することが企業コンプライアンス上求められます 。したがって、企業が自社でAI学習を行う際には、そのデータ収集と解析のプロセスが純粋に情報処理や技術開発のためのものであることを、内部の仕様書や企画書で明確に定義しておくことが防衛策となります。
生成・利用段階におけるアウトプットの著作権侵害リスクと対策
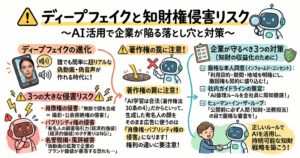
学習段階が適法であったとしても、生成AIがコンテンツを出力し、それをビジネスで利用する段階においては全く異なる法的基準が適用されます。機械学習への著作権法の例外規定が顕著に問題となるのは、実は機械学習そのものの行為よりも、AIによって既存の著作物の創作的表現と類似する表現が出力される場面、すなわち「利用段階」においてなのです 。
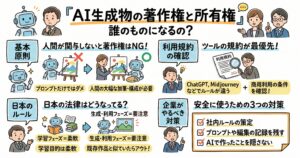
生成AIによるコンテンツの知的財産権に関する法的整理は、主に二つの論点に大別されます。一つ目は「生成されたコンテンツそのものに著作権が認められるのか」という著作物性の問題であり、二つ目は「生成されたコンテンツが他人の既存の著作物と似ている場合、著作権侵害が成立するのか」という他者権利への侵害問題です 。
一つ目の著作物性について、現行の日本の著作権法では、著作物は「人間の思想又は感情を創作的に表現したもの」と定義されています。したがって、人間が単に短いプロンプト(指示文)を入力し、AIが自動的に生成しただけの画像や文章には、人間の創作的意図が十分に反映されていないとみなされ、原則として著作権は発生しません。しかし、人間がAIをあくまで「道具」として使いこなし、出力結果に対して加筆修正を行ったり、プロンプトの調整を幾度も繰り返して表現を追い込んだりした場合には、そこに人間の創作的寄与が認められ、例外的に著作物として保護される余地があります。企業がAI生成物を自社の資産として囲い込もうとする場合、この「人間の創作的寄与の度合い」をどのように証明できるかが実務上の課題となります。
二つ目の他者の著作権侵害リスクについては、より深刻な対応が求められます。AIが生成した画像や文章が、既存の著作物と同一または類似している場合、直ちに著作権侵害(複製権や翻案権の侵害)となるわけではありません。著作権侵害が成立するためには、客観的な「類似性」に加えて、既存の著作物をもとにして作成したという「依拠性」が証明される必要があります。AIが学習データとして特定のクリエイターの作品を大量に読み込んでおり、意図的にその作風を再現させるようなプロンプトが用いられた場合、依拠性が認められる可能性が極めて高くなります。
法的な視点からは、機械学習を行う行為と、その結果生じる学習済みモデルを用いた出力行為を一体のものとして違法性を評価することは困難であり、利用段階での行為に対して個別に責任を追及すれば足りると考えられています 。これは企業にとって、AIの開発・導入と、その運用・公開のフェーズでそれぞれ異なるチェック体制を敷く必要があることを意味します。実務的な対策としては、AIが生成したコンテンツをそのまま外部に公開するのではなく、必ず人間の担当者が既存の著作物との類似性がないかスクリーニングを行うプロセスを設けることが不可欠です。また、特定の作家名や作品名をプロンプトに入力することを社内規程で禁止するなど、依拠性を意図的に生じさせないためのガイドライン策定が強く推奨されます。
個人情報保護法と生成AI:仮名加工情報と匿名加工情報の厳密な使い分け
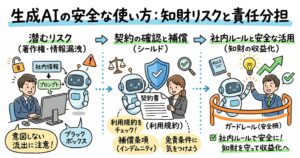
著作権法と並んで、生成AIの利活用において企業が最も神経を尖らせなければならないのが、個人情報保護法に基づくプライバシーの保護とデータガバナンスの徹底です。企業が保有する顧客の購買履歴、行動ログ、人事データなどをAIの学習データとして用いる場合、そこには膨大な個人情報が含まれています。AIの能力を最大限に引き出すためには良質なデータが不可欠ですが、その取り扱いを誤れば重大な法令違反やレピュテーションリスクに直結します。
この点に関して、個人情報保護委員会は2023年(令和5年)6月2日に「生成AIサービスの利用に関する注意喚起等について」という重要な声明を発表しました 。この注意喚起では、企業や行政機関などの事業者が生成AIサービスを利用するにあたり、自社が保有する個人データを安易にAIのプロンプトとして入力したり、学習データとして提供したりすることの危険性に警鐘を鳴らしています。特に、入力したデータがAI事業者のモデル学習に二次利用される設定になっている場合、意図せず自社の顧客情報が外部に漏洩し、他のAIユーザーの回答として出力されてしまうリスクがあることが指摘されました 。
企業がこのリスクを回避しつつ、自社のデータを安全にAI学習に利活用するためには、個人情報保護法が定める「匿名加工情報」および「仮名加工情報」という二つの概念を正確に理解し、実務において厳密に使い分けることが求められます。これら二つの情報形態は名称が似ているため混同されやすいのですが、法的な規制の強度や利用できる範囲が大きく異なります 。
まず「匿名加工情報」とは、一定の措置を講じて特定の個人を識別することができないように個人情報を加工して得られる情報であり、かつ、元の個人情報を絶対に復元することができないように不可逆的な処理を施したものを指します(個人情報保護法第2条第6項)。匿名加工情報の最大の利点は、情報から個人の特定性が完全に排除されているため、本人の同意を取得することなく第三者へ提供することが可能となる点にあります(同法第44条)。例えば、自社の顧客データを外部のAI開発ベンダーに提供し、共同で需要予測モデルを構築するようなケースでは、原則としてこの匿名加工情報化が必須となります。ただし、加工の実務は非常に厳格です。単に氏名や連絡先を削除するだけでなく、残った属性情報(年齢、性別、居住地域、特異な購買履歴など)の組み合わせから特定の個人が推測され得る場合には、データを丸めたり、特異な記述を削除したりして、個人が特定できない状態を完全に担保しなければなりません 。さらに、匿名加工情報を第三者に提供する際は、それに含まれる情報の項目と提供方法を公表し、提供先に対して匿名加工情報である旨を明示する義務が課せられます 。
一方、「仮名加工情報」とは、他の情報(照合キーなど)と照合しない限り、特定の個人を識別することができないように加工された情報のことを指します。仮名加工情報は、元の個人情報を復元できないようにする匿名加工情報とは異なり、社内に厳重に保管された対照表を用いれば元の個人を特定できる状態にあります。そのため、匿名加工情報よりも規制は厳しくなりますが、生の個人情報に比べれば利用目的の変更が柔軟に行えるなどのメリットがあります 。
しかし、仮名加工情報には極めて重要な制約があります。それは、法令に基づく場合を除き、原則として第三者提供を行うことができないという点です(同法第42条)。この規定には例外がなく、たとえ本人の同意を得たとしても、仮名加工情報の状態のまま第三者に提供することは認められません 。したがって、仮名加工情報はあくまで「社内でのクローズドな情報分析や、自社専用のAIモデルの内部学習」を目的とした活用が想定されています 。自社内で完結するAI開発プロジェクトであれば、仮名加工情報は非常に扱いやすいデータフォーマットと言えます。なお、業務委託や事業承継、あるいはグループ企業間での共同利用といった特定の枠組みにおいては、提供元の事業者と提供先の事業者を一体として取り扱うことに合理性があるため、例外的に仮名加工情報の提供が可能とされています 。企業は、AI学習に用いるデータを社内で完結させるのか、外部のエコシステムと連携するのかを見極め、適切な加工手法を選択する高度な判断が求められます。
個人データの学習とプライバシー:生成AIの透明性と責任
個人データの学習とプライバシー:生成AIの透明性と責任 AIモデルが個人情報を含むデータを学習すると、生成物に個人を特定できる情報が含まれる場合があり、プライバシー侵害や個人情報保護法違反の問題が生じます。企業は学習データに個人データが含まれるか確認し、適切に匿名化するか、本人の同意を得て利用する必要があります。
前述の指定テキストにもある通り、AIモデルに個人情報をそのまま学習させることは、プライバシーの観点から極めて高いリスクを伴います。一度AIの巨大なネットワークの中に組み込まれた個人情報を、後からピンポイントで削除することは技術的に非常に困難であるため、入口の段階でのデータクレンジングと同意取得のプロセスが決定的な意味を持ちます。そして現在、この問題は単なる企業内のコンプライアンスにとどまらず、社会全体に向けたAIの「透明性」と「説明責任(アカウンタビリティ)」の議論へと発展しています。
日本政府や内閣府知的財産戦略推進事務局においても、生成AIの適切な利活用と知的財産の保護、そして透明性の確保に関する制度設計が急ピッチで進められています。特筆すべきは、この透明性に関するルールが、国内企業のみならず海外事業者に対しても適用される方針が示されている点です。具体的には、日本国内に本店又は主たる事務所を有しない海外の生成AI事業者であっても、その生成AIシステムやサービスが日本に向けて提供されており、日本国民が広く利用できる状態にある場合には、日本の指針やルールを遵守するよう求める見解が示されています 。これにより、国内外を問わず、同じ競争環境下でプライバシーと知財が保護される枠組みの構築が目指されています。
政府が推進する透明性ルールの核心部分には、「コンプライ・オア・エクスプレイン(原則の遵守、あるいは遵守しない場合の理由の説明)」という考え方が導入されています 。生成AIの開発や学習において、他者の知的財産権や個人のプライバシーを尊重することは、もはや議論を待たない大原則です。もし、AI事業者が自社のサービス利用規約等において、この原則の適用を撤廃または制限するような規定(いわゆるオーバーライド条項)を設けている場合、単に「規約に同意したから」という主張だけでは説明責任を果たしたことにはなりません。なぜそのような例外規定を設け、原則を制限する必要があるのかについて、ユーザーや社会に対して合理的かつ詳細な説明(エクスプレイン)を行うことが強く求められます 。
さらに、政府は各AI事業者の情報開示の姿勢や、透明性確保に向けた具体的な取り組み状況を定期的に評価し、優良な事業者に対しては政府が実施する事業や制度において一定のインセンティブを設ける方針も検討しています 。議論の俎上には、AIモデルがどのようなデータセットを学習したのかという「概要開示対象事項」の設定や、ユーザーがどこまでデータの出所を問い合わせることができるかという「開示要求可能事項」、そしてその開示の粒度をどのレベルに設定すべきかといった、実務に直結する高度なテーマが含まれています 。また、リソースが限られているスタートアップ企業に対して、どのような配慮措置を設けるべきかという点も重要な検討課題となっています 。
企業としては、自社でAI基盤モデルを開発する立場であれ、他社のAIサービスをAPI経由で組み込んで事業を展開する立場であれ、利用するAIがどのようなデータで学習され、プライバシーや知財権のクリアランスをどのように行っているのかを把握しておく必要があります。ブラックボックス化されたAIを盲目的に利用するのではなく、その成り立ちに対する透明性をエンドユーザーに対して保証できる体制を整えることが、今後のビジネスにおける最低限の参加資格となるでしょう。
知財の収益化戦略:データ資産の価値評価と競争優位性の構築
ここまでに解説してきた著作権法への対応、個人情報保護法に基づく適切なデータ加工、そしてAIモデルの透明性と説明責任の確保。これらの一見すると厳格でコストのかかる防御的なコンプライアンス要件は、視点を変えれば、企業の「知財の収益化」を強力に推進するための極めて有効な攻めの戦略基盤となります。法令を遵守し、権利関係がクリーンな状態に整備されたデータは、それ自体が他社には容易に模倣できない独自の価値を持つようになるからです。
データ収益化(データ・マネタイゼーション)とは、組織が保有する膨大なデータ資産と人工知能技術を掛け合わせることで、新たな価値を創造し、実際のビジネス成果として具現化する企業能力のことを指します 。従来、データは単なるITシステムの副産物や記録として扱われがちでしたが、現在では経営の根幹を支える「戦略的な資産」として明確に位置づける必要があります。この戦略的資産を最大限に活用するためには、データを「データ製品(データプロダクト)」として扱う、ユーザー中心のアプローチが不可欠です 。
権利関係が整理され、プライバシーリスクが排除された高品質なデータプロダクトが社内に構築されると、それは特定の部門だけでなく、多様なアプリケーションや事業部門から横断的に利用できるようになります 。これにより、社内の業務効率化による内部の費用対効果の改善がもたらされるだけでなく、高度な需要予測やパーソナライズされた顧客体験の提供が可能となります。さらに、その価値は社内にとどまりません。法的に安全なデータプロダクトは、外部のパートナー企業とのデータ連携を容易にし、強固なパートナー・エコシステムを構築するための共通言語となります。データに基づいた価値交換システムは、エコシステム全体の経済的価値を押し上げ、ひいてはデータ自体をライセンス提供するといった新しい収益源(新規ビジネスモデル)の創出へと波及していくのです 。
逆に言えば、権利関係が曖昧なデータや、プライバシー侵害の懸念を払拭しきれないAIモデルを用いてビジネスを展開することは、砂上の楼閣に等しいと言えます。いかに先進的なアルゴリズムを用いていようとも、法令違反のリスクを内包したサービスは市場からの信頼を得られず、最終的な収益化の道は閉ざされてしまいます。組織は、データの収集からAIの学習、そして出力に至るまでの全プロセスにおいて高い透明性と倫理性を示し、データ・プライバシーへの真摯な配慮を宣言し、最新の規制動向を遵守し続ける必要があります。データの出所や権利処理のプロセスを安全かつセキュアに保つことで、組織は初めてステークホルダーからの「データとAIに対する確固たる信頼」を構築することができます 。AI時代における企業の競争優位性は、アルゴリズムの優劣のみならず、この「クリーンなデータを管理し、社会的な信頼を担保する能力」にこそ宿っているのです。
実務における体制構築:社内ガイドラインの策定と知財人材の役割
生成AIという革新的なテクノロジーを自社の成長エンジンとして組み込むためには、ここまで述べてきた法的要件を実務レベルで実行するための社内体制の構築が不可欠です。法務部門、知的財産部門、そして実際にAIを開発・利用する事業部門やIT部門が緊密に連携し、全社的な視点でデータガバナンスを効かせる仕組みを作らなければなりません。
具体的なアクションの第一歩は、実効性のある「生成AI利用ガイドライン」の策定です。このガイドラインには、入力してはならない機密情報や個人データの定義(仮名加工情報と匿名加工情報の手順を含む)、既存著作物との類似性チェックの義務化、利用する外部AIサービスの選定基準などを明確に記載する必要があります。特に、AIの出力結果をそのまま商用利用する際のリスク評価フローを構築し、最終的な責任は常に人間が負うという「ヒューマン・イン・ザ・ループ(人間の関与)」の原則を社内に浸透させることが重要です。
また、知財部門の役割も大きく変化しています。従来の特許出願や商標管理といった定型的な業務に加え、データという無形資産の権利処理、AIベンダーとの複雑なライセンス契約の交渉、オープンソースデータの利用規約の精査など、より広範で高度な法的判断が求められるようになっています。法務と知財の境界線が曖昧になる中で、テクノロジーの進化を正しく理解し、法律の文脈に翻訳できるハイブリッドな知財人材の存在が、企業の知財収益化戦略の成否を握ると言っても過言ではありません。
生成AIの進化は日進月歩であり、それを取り巻く法制度や政府のガイドラインも常にアップデートされ続けています。企業は一度体制を構築して満足するのではなく、最新の法改正や判例の動向、個人情報保護委員会や内閣府の発表を継続的にモニタリングし、自社のルールをアジャイルに見直していく柔軟性が求められます。適法かつ倫理的に構築されたAIモデルとクリーンなデータ資産は、間違いなく企業に新たなビジネス価値をもたらします。イノベーションとコンプライアンスを高い次元で両立させ、データの真の価値を解放することこそが、次世代を勝ち抜く企業に課せられた最大のミッションなのです。
(この記事はAIを用いて作成しています。)
参考文献リスト
- 生成AIによるコンテンツの知的財産権の取り扱いと法的整理, https://www.docusign.com/ja-jp/blog/lawyer-explains-Intellectual-Property-Rights-for-Generative-AI-Content
- 生成AIの適切な利活用等に向けた知的財産の保護及び透明性に関する議論, https://public-comment.e-gov.go.jp/pcm/download?seqNo=0000305362
- 機械学習と著作権法30条の4の適用に関する考察, https://www.publication.law.nihon-u.ac.jp/pdf/property/property_18/each/08.pdf
- 生成AIサービスの利用に関する注意喚起等について(令和5年6月2日), https://www.ppc.go.jp/news/press/2023/230602kouhou
- 仮名加工情報と匿名加工情報の違いとは, https://www.authense.jp/professionalinsights/bt/privacy/76/
- データ収益化戦略をデータ製品とAIで加速する方法, https://www.ibm.com/jp-ja/think/insights/how-to-accelerate-your-data-monetization-strategy-with-data-products-and-ai