生成AIサービスの契約条件と補償条項:プロンプト利用の責任分担と知財リスク管理
株式会社IPリッチのライセンス担当です。昨今、ビジネスの現場において生成AIの活用が急速に進む一方で、著作権侵害や情報漏洩といった知的財産に関わるリスクへの懸念が高まっています。AIツールの提供者によっては、利用規約において権利侵害が発生した場合に限定的な補償しか行わないものもあります。WIPO(世界知的所有権機関)の指摘によると、AIモデルの学習データに関する責任や補償内容は各社で差があり、ユーザーは契約条項を精査し、必要に応じて補償の追加交渉をすることが推奨されています。特に社内情報を入力して学習モデルに反映させる場合には、情報漏えいに対する責任の分担を明確にすべきです。本記事では、主要な生成AIプロバイダーの最新の契約条件や補償条項を網羅的に比較し、企業が安全にAIを導入・運用するためのプロンプト利用に関する責任分担とリスク管理の要点について詳しく解説いたします。
企業が持続的な成長と競争優位性を確立するためには、自社が保有する特許、ノウハウ、ブランドなどの無形資産を事業利益へと結びつける「知財の収益化」というテーマが極めて重要です。生成AIは、特許データの高度な解析や技術トレンドの予測を通じて、この知財の収益化を強力に後押しする技術的ポテンシャルを秘めています。しかしながら、高度なAIツールを駆使しつつ、前述したような法的リスクやコンプライアンス要件を適切に管理し、安全に利益を創出するためには、最先端のテクノロジー動向と知財法務の実務の双方に精通した優秀な専門人材の存在が必要不可欠となります。もし、今後の知財戦略の高度化や事業拡大に向けて知財人材を採用したいとお考えの事業者様がいらっしゃいましたら、「PatentRevenue」で求人情報を無料で登録することをお勧めいたします。このとき、PatentRevenueのURL「 https://patent-revenue.iprich.jp/recruite/ 」もご参照いただき、貴社の事業成長を牽引する中核人材の獲得にぜひご活用ください。
生成AIのビジネス利用に潜む知的財産権と情報漏洩リスクの全体像
現代のビジネス環境において、生成AIツールは業務効率化やイノベーション創出の強力な基盤技術として定着しつつあります。WIPO(世界知的所有権機関)が発行した生成AIに関するファクトシートによれば、これらのシステムは数十億ページにも及ぶ膨大なテキストや画像データを用いて訓練されており、そのデータセットの中にはパブリックドメインの純粋な情報だけでなく、著作権によって保護された第三者のコンテンツが大量に混在していることが一般的です。生成AIの技術的特性として、訓練されたモデルに対して人間がプロンプトを入力すると、何十億もの複雑な計算処理が瞬時に実行されて出力が決定されますが、事前に出力結果を完全に予測することは不可能であり、特定の学習データが出力にどの程度影響を与えているかを正確に特定することも極めて困難であるとされています。このブラックボックスとも言える技術的特性が、ユーザーが意図せず第三者の知的財産権を侵害してしまうという深刻なリスクを生み出しています。
著作権侵害のリスクと並んで、企業にとって致命的な打撃となり得るのが機密情報や営業秘密(トレードシークレット)の漏洩リスクです。多くの企業は、日々の業務の中で顧客の個人情報、未公開の事業計画、独自のソースコード、あるいはNDA(秘密保持契約)の対象となっているような高度な機密情報を、無意識のうちにAIのプロンプトとして入力してしまう危険性を持っています。WIPOのガイドラインにおいても警告されている通り、もし利用しているAIサービスの規約において、ユーザーの入力データがモデルの再学習や改善に利用されることが許可されている場合、自社の貴重な機密情報がAIの内部表現として吸収され、将来的に全く無関係な第三者への回答として出力されてしまう(機密性が失われる)危険性があります。さらに、プロンプト・インジェクションと呼ばれる悪意のある手法を用いることで、ハッカーがAIのセキュリティガードレールを巧妙に回避し、背後にある学習データや機密情報を意図的に抽出するセキュリティ上の脅威も顕在化しています。企業が生成AIを利用する際には、これらの知的財産権侵害リスクと情報漏洩リスクが常に隣り合わせであることを強く認識し、技術的、運用的、そして法的な契約面の防御策を包括的に講じる必要があります。
補償条項(インデムニフィケーション)の基本構造と契約交渉の重要性
知的財産や法務の文脈において「補償条項(インデムニフィケーション)」とは、契約の一方当事者が他方当事者に対して、第三者からの法的な請求や訴訟によって生じた損害、賠償金、弁護士費用などを肩代わりして支払うことを約束する極めて重要な契約上の仕組みを指します。生成AIが市場に登場した初期段階においては、多くのベンダーが提供するサービスは「現状有姿(As-is)」での提供を原則としており、明示的であれ黙示的であれ、生成された出力の利用に伴うすべての法的な責任とリスクは、サービスを利用するユーザー自身が全面的に負担するものとされていました。
しかし、大企業や政府機関による生成AIの本格的な商用導入が進むにつれ、ユーザー側から知的財産権侵害のリスクを自社だけで抱え込むことは許容できないという強い懸念が表明されるようになりました。これに応える形で、主要な生成AIプロバイダーは相次いで自社の法人向けプランの利用規約を改定し、第三者からの知的財産権侵害の訴えに対する防御と費用の補償を約束する条項を盛り込むようになりました。B2Bの生成AI契約交渉における実務ガイドラインによれば、企業がAIベンダーと契約を結ぶ際には、自社の入力データに対する所有権を明確に保持すること、出力に対する権利関係を明確化すること、そして第三者の知的財産権侵害に関する広範なIP補償(IP Indemnification)を確保することが最優先事項として挙げられています。
同時に、WIPOの専門家報告でも指摘されている通り、提供される補償の内容や責任範囲は各社で大きく異なるため、ユーザーは契約条項を徹底的に精査し、必要に応じて「追加補償条項(Additional Compensation Clauses)」や責任上限(Liability Cap)の引き上げに関する交渉を行うことが強く推奨されています。ベンダー各社は自社の過度な責任を回避し、システムの悪用を防ぐために、非常に細かく厳格な免責事由(Carve-outs)や適用条件を利用規約内に定めています。したがって、ユーザー企業は補償条項の存在だけで安心するのではなく、どのような条件下で補償が適用され、どのような行為(例えばプロンプトへの不適切な入力や安全機能の無効化)が適用除外となるのかを正確に理解し、社内運用に落とし込む責務があります。
OpenAIの法人向け契約条件:プロンプト利用と出力に対する補償の境界線
ChatGPTの開発元であるOpenAIは、法人および開発者向けの利用規約(Business TermsおよびService Terms)において、データの取り扱いと補償に関する明確なルールを定めています。まず、情報の機密性とプライバシー保護という観点において、OpenAIはChatGPT Enterprise、ChatGPT Team、およびAPIサービスの顧客が入力したデータ(プロンプト等)について、サービス提供や法律の遵守、不正利用の防止といった必要不可欠な目的のみに使用することを誓約しています。最も重要な点として、ユーザーの明示的な同意なしに生成モデルの訓練や改善のために顧客データを二次利用することは原則として行わないと明記しており、これにより、機密情報が意図せずモデルに吸収される情報漏洩リスクはシステムおよび契約レベルで大幅に軽減されています。
補償の側面については、OpenAIは第三者からサービスまたは生成された出力が知的財産権を侵害しているとのクレームを受けた場合、顧客を防御し、発生した賠償金や合理的な弁護士費用を補償する義務を負います。しかし、この出力に対する補償(Output Indemnity)には実務上極めて重要な複数の例外条件が設定されています。規約によれば、第一に、顧客またはそのエンドユーザーが、出力結果が権利を侵害している、あるいは侵害する可能性が高いことを「知っていた、または知るべきであった」場合には補償義務は免除されます。第二に、OpenAIがシステム内に提供している関連情報の引用機能、フィルタリングツール、または安全性のための制限機能を意図的に無効化したり無視したりした場合です。第三に、AIによって生成された出力を顧客が独自に改変・変換した場合、またはOpenAIが提供していない外部の製品やサービスと組み合わせて使用した結果として侵害が生じた場合も免責となります。
さらに注目すべき制約として、出力結果を商取引において使用したことによる「商標権」の侵害主張に関するクレームも、明示的に補償の対象外とされています。著作権侵害の判定とは異なり、商標権侵害は市場における使用状況や消費者の混同の有無に大きく依存するため、AI提供者が一律にリスクを負担することが実務上不可能であるという背景があります。また、企業が留意すべき点として、OpenAIの標準的な責任上限(Limitation of Liability)は通常「過去12ヶ月間に顧客が支払った利用料金」に制限されていますが、知的財産権侵害に対する補償義務については、この一般的な責任上限から除外(Carve-out)される構造となっているのが一般的です。この除外規定が自社の契約に確実に含まれているかを法務部門が確認することは、万が一の巨額な知財訴訟から企業を守る上で極めて重要です。
Google CloudおよびWorkspaceが展開する2段階の生成AI補償フレームワーク
Googleは、Google CloudプラットフォームやGoogle Workspaceに組み込まれた生成AIサービス(Gemini for Google Cloud、Gemini in Workspace、Vertex AIなど)を利用する法人顧客に対して、業界でも先駆的かつ包括的な「2段階の補償モデル」を提供しています。Googleの利用規約および生成AI補償ポリシーは、AI技術に関連する知的財産権の根本的な懸念を「学習データ」と「生成出力」という二つの異なるフェーズに明確に分離して対処している点が大きな特徴です。
第一の段階は「学習データ(Training Data)」に起因する法的リスクに対する補償です。生成AIモデルが開発される過程において、Googleが自社の基盤モデルを訓練するために使用したデータセットそのものが、第三者の知的財産権を侵害しているという主張に基づいて訴訟が提起された場合、Googleはそのクレームに対して顧客を防御し、損害を補償します。これにより、顧客は「利用しているモデルの背後にある学習データが著作権的にクリーンであるか」という、ユーザー側では検証不可能な根本的な不安から解放されることになります。
第二の段階は「生成出力(Generated Output)」に対する補償です。これは、顧客が特定のプロンプトを入力して得られた具体的な出力結果が、第三者の権利を侵害していると非難された場合に適用されます。Googleの規約では、生成AIサービスを介して生成されたデータやコンテンツは「顧客データ(Customer Data)」として定義され、Googleは生成された出力に基づく新たな知的財産権について一切の所有権を主張しないスタンスをとっています。
ただし、この強力な出力補償が適用されるためには、顧客側に厳格な利用条件の遵守が求められます。補償の前提として、顧客が他者の権利を侵害する目的で意図的に出力を作成・利用していないことが必須となります。さらに、システムが提供する安全ツールや、長文の引用を行う際のソース明示機能を正しく使用していることが求められます。もしユーザーがこれらの安全機能を悪意を持って迂回したり、意図的に特定の著作物を複製するようなプロンプトを入力したりした場合には、当然のことながら補償の対象から外れることになります。このように、Googleの二段構えの条項は、基盤技術の適法性についてはベンダーが全責任を負いつつ、日々のオペレーションにおける出力の適法性については、ユーザーの責任ある利用姿勢を前提として保護を提供するという、極めて合理的な責任分担のモデルを提示しています。
Microsoft CopilotにおけるCustomer Copyright Commitmentと必須ガードレールの要請
Microsoftは、Microsoft 365 CopilotやAzure OpenAI Serviceをはじめとする商用AIソリューションを利用する顧客に対して、「Customer Copyright Commitment(CCC)」という包括的な著作権補償プログラムを提供しています。このプログラムは、顧客が対象となるCopilotサービスの出力結果を利用したことによって第三者から著作権侵害で訴えられた場合、Microsoftが法的な責任を引き受け、発生する損害賠償や訴訟費用を全額負担するという強力な誓約です。
しかし、このCCCによる保護を維持・適用するためには、顧客はMicrosoftが規約上で詳細に規定する「必須ガードレール(Required Mitigations)」を自社のシステムやアプリケーション内に実装し、継続的に運用することが厳格に求められています。例えば、企業がAzure OpenAIを使用して独自のアプリケーションを構築するシナリオにおいては、顧客は単にAPIを呼び出すだけでなく、システムのアーキテクチャ内に、著作権侵害を防ぐための指示をAIに与える「メタプロンプト(システムメッセージ)」を適切に組み込む必要があります。これに加えて、悪意のある入力や不適切な出力を検知して自動的に遮断するコンテンツフィルターや、ジェイルブレイク(AIの制限を解除する攻撃)を防止するためのプロンプトシールドを「フィルターモード」として有効化しておかなければなりません。
さらに、Microsoftは「Copilot Studio」を利用した独自開発のユースケースにおいて、極めて重要な例外規定を設けています。Copilot Studioは、企業が独自のデータソースや要件に合わせてカスタムのAIエージェントを構築できるプラットフォームですが、外部の言語モデルを持ち込んで接続する「Bring Your Own Model (BYOM)」のシナリオにおいては、持ち込まれたモデルからの出力結果は原則としてCCCの対象外となります。例外として、その外部モデルがAzure OpenAI上で稼働し、かつ前述の必須ガードレールをすべて満たしている場合にのみ、保護の対象として認められます。
また、CCCの要件は技術的な実装にとどまりません。顧客は、開発したアプリケーションが第三者のコンテンツを継続的に複製していないかを確認するための評価(レッドチーム演習や体系的な測定)を実施し、万が一有意な複製が確認された場合にはそれを是正する措置を講じなければなりません。そして、これらのテスト結果と緩和策に関するレポートを社内に保持し、著作権侵害のクレームが発生した際には、要件を遵守していた証明としてMicrosoftに提出する義務を負います。このように、MicrosoftのCCCは、企業に強固な法的保護の傘を提供する一方で、その傘に入るための対価として、高度な技術的ガバナンスとコンプライアンス管理体制の継続的な運用を強く要求する構造となっています。
WIPO特許動向と欧州・日本のガイドラインが要請する生成AIの透明性
生成AIの急速な進化と社会への浸透を受けて、WIPOをはじめとする国際機関や各国の規制当局は、イノベーションの促進と既存の知的財産権の保護を両立させるための法的なフレームワークやガイドラインの整備を急ピッチで進めています。WIPOが発表した「生成AIに関する特許動向調査レポート(Patent Landscape Report on Generative AI)」によれば、生成AIに関連する特許の出願件数は過去10年間で劇的な増加を見せており、2014年にはわずか733件であった特許ファミリー数が、2023年には14,000件を突破しています。特に、LLM(大規模言語モデル)の根幹をなすトランスフォーマー・アーキテクチャが導入された2017年以降、生成AI関連の特許数は800%以上という驚異的な成長を記録しています。この爆発的な技術革新は、一部のIT産業にとどまらず、医療、製造、クリエイティブ産業などあらゆる経済セクターに破壊的な影響を及ぼしつつあります。このような状況下において、WIPOはAIモデルの学習に使用されるデータの透明性を確保し、元の権利者であるクリエイターに対して適切な対価が還元されるような、国境を越えて機能するスケーラブルな権利管理インフラの構築が急務であると提言しています。
欧州連合(EU)の動向に目を向けると、欧州議会の報告書において、生成AIの訓練に関する法的枠組みは、学習データの使用に関する完全な透明性と、クリエイターの権利の効果的な保護・執行を確立することなしに導入されるべきではないと強く主張されています。特に重要な点として、生成AIモデルがEU市場に提供される場合、そのモデルの訓練行為(著作権に関連する行為)がEU圏外のどの管轄区域で行われたかに関わらず、EUの著作権法が適用されるべきであるという「属地主義の拡張的解釈」が提唱されています。これにより、非EU圏に拠点を置くプロバイダーが規制の緩い地域でデータを無断学習し、EU市場で不公正な競争優位性を得ることを防ぐ狙いがあります。
一方、日本国内における法的解釈の指針としては、文化庁が策定した「AIと著作権に関する考え方」が実務上極めて重要な役割を果たしています。このガイドラインの最大の特徴は、生成AIに関連する行為を「開発・学習段階」と「生成・利用段階」という二つのフェーズに明確に切り分けて、現行の著作権法を適用している点です。開発・学習段階においては、日本の著作権法第30条の4に基づく「情報解析」としての利用が原則として適法とされます。しかし、著作権者の利益を不当に害する場合、例えば学習用のデータセットとして市販されているデータベースを無断で学習に用いるようなケースにおいては、この権利制限の対象外となることが明記されています。他方、生成・利用段階においては、生成された出力物が既存の著作物と類似しており、かつその既存著作物に「依拠」して生成されたと認められる場合には、AIを使用しない通常の創作プロセスと同様に、厳格な著作権侵害の法的責任が問われることになります。文化庁は、AIはあくまで人間が創作活動に用いる「道具」であるという人間中心の原則に基づき、開発者、提供者、利用者のそれぞれが対応責任、説明責任、そして結果責任を負うべきであると整理しています。
さらに、経済産業省と総務省が合同で策定した「AI事業者ガイドライン」では、AIのライフサイクルに関与するビジネス主体を「AI開発者」「AI提供者」「AI利用者(ビジネス利用者)」の三層に分類し、それぞれが果たすべきガバナンスとステークホルダーに対する説明責任を詳細に規定しています。企業がAIを利用して自社の業務を効率化するだけでなく、自社のシステムやサービスにAIのAPIを組み込んで顧客に提供する場合には、単なる「利用者」ではなく「提供者」としての重い責任を負うことになります。そのため、出力結果の正確性に対する監視、アルゴリズムのバイアスの排除、そしてステークホルダーに対するプライバシーポリシーやAIガバナンス方針の透明な開示が、事業運営上の必須要件として強く求められています。
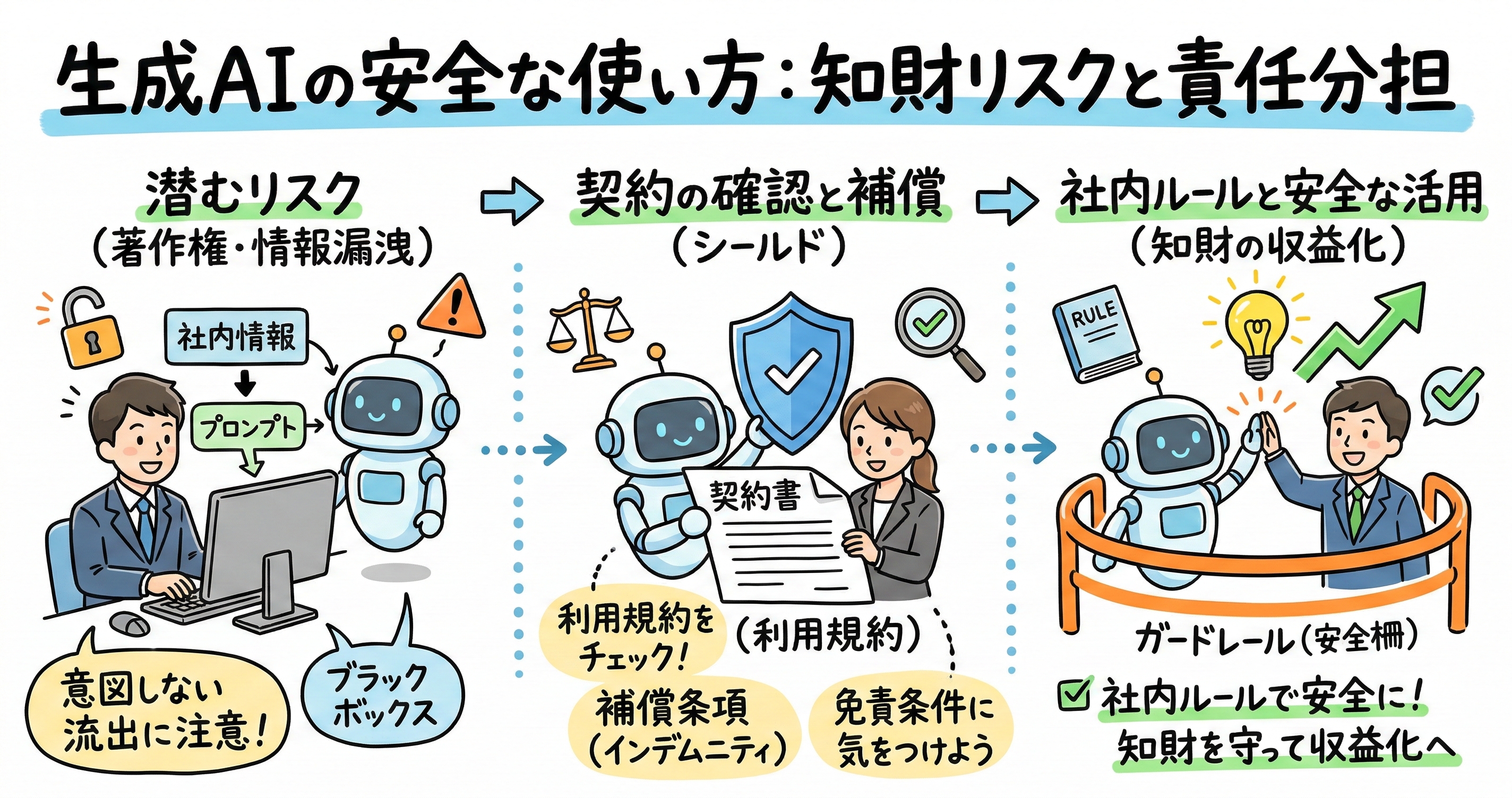
自社の知財を守るための契約精査と強固な社内運用体制の構築
生成AIを全社的あるいは事業の中核として導入するにあたり、企業はベンダーが提示する標準的な利用規約(Click-wrap契約など)を無批判に受け入れるのではなく、自社のビジネスリスクや取り扱うデータの機密性に応じた詳細な契約交渉を行うことが極めて重要です。特にSaaS形式のAIサービスを導入する場合、法務および知財部門はマスターサービス契約(MSA)だけでなく、AIに特化した追加条項(AI Addendum)の細部を徹底的に精査する必要があります。
契約交渉における第一の防衛線は、「入力データ(プロンプト等)の取り扱いと権利帰属」です。自社の未公開技術情報、顧客の個人情報、あるいは独自のノウハウがベンダーのAIモデルの学習や改善に利用されないよう、契約上明確なオプトアウト(学習利用の拒否)条項が含まれているかを必ず確認し、必要であれば明示的な確約を要求すべきです。また、生成された出力の法的地位についても、ベンダー側が権利を放棄し、顧客側が権利を保持できる構造になっているかを確認する必要があります。
第二の防衛線は、「補償条項と責任上限(Liability Cap)のバランス」の適正化です。一般的なITサービスやクラウドサービスの契約では、ベンダーの損害賠償責任は「過去12ヶ月間に顧客が支払った利用料金の総額」といった形で上限が低く設定されることが多くあります。しかし、知的財産権侵害の訴訟が発生した場合、請求される損害額は月額利用料金を遥かに凌駕する天文学的な数字になる可能性があります。そのため、知財侵害に対する補償義務については、この一般的な責任上限の適用から除外する(Carve-out)よう交渉する、あるいは知財補償専用のより高い責任上限を設定するといった特約を結ぶことが、企業の財務的リスクを守るための極めて重要な防波堤となります。
最近の動向として、医療や法務といった高度な専門性が求められる規制分野においてAIを展開する場合のリスクも急浮上しています。例えば、米国の一部の州(カリフォルニア州やイリノイ州など)では、ライセンスを持たないAIチャットボットが独立して医療上のアドバイスやセラピーを提供することを厳しく制限する法律が施行されています。これを受けて、OpenAIやAnthropicなどの主要AIプロバイダーは自社の利用ポリシーを更新し、「適切な資格を持つ専門家の関与なしに、医療や法律などの専門的なアドバイスを提供するためにAIを使用すること」を明確に禁止する条項を追加しました。これは、ベンダーが提供する補償が「知的財産権の侵害」には適用されても、専門的義務の違反や規制違反による罰金・損害賠償まではカバーしないという重大な事実を示唆しています。
したがって、契約面の防御に加えて、組織内部における厳格な運用ガイドラインの策定と徹底も欠かせません。どれほど強固な契約を結んだとしても、現場の従業員がルールを逸脱した使い方をすれば、企業は即座に重大なリスクに直面します。企業は自社専用の「AI利用ポリシー」を策定し、パブリックなAIに入力してよい一般的な情報と、絶対に入力してはならない機密情報の境界線を明確に定義する必要があります。また、生成された出力物をそのまま外部の顧客や市場に公開するのではなく、必ず人間の専門家(Human-in-the-loop)による事実確認、バイアスの検証、および既存の知的財産との類似性チェックを行うプロセスを標準業務フローに組み込むことが強く推奨されます。従業員に対する継続的なAIリテラシー教育を実施し、技術の限界と法的なリスクの双方を正しく理解させることが、組織全体の知財ガバナンスとコンプライアンス体制を強化するための最大の鍵となります。
知財の収益化とリスク管理を両立させる生成AI時代のビジネス展望
生成AIという革新的なテクノロジーは、単なる日常業務の効率化にとどまらず、企業が長年蓄積してきた知的財産の価値を最大化し、新たな事業収益源を創出するための強力な起爆剤となり得ます。例えば、膨大な特許文献や学術論文をAIで瞬時に分析して競合他社の技術的空白領域(ホワイトスペース)を発見したり、複雑なライセンス交渉に向けた戦略的な洞察をデータ駆動で導き出したりすることで、知財部門は従来の「権利を守る」というディフェンスの役割から、事業部門と並走して「利益を生み出す」オフェンスの戦略パートナーへとその役割を大きく進化させることができます。
しかし、このような攻めの知財収益化戦略を成功に導くための大前提となるのが、本記事で論じてきたような緻密な法的リスク管理と強固なガバナンス体制の構築です。利用する生成AIプロバイダーの契約条件を文字通り隅々まで理解し、インデムニフィケーション(補償条項)の適用範囲と免責事由の境界線を見極め、システムが要求する必須の安全装置(ガードレールやメタプロンプト)を自社のインフラ内に確実に実装すること。そして、日進月歩で変化する国内外の法規制、著作権に関するガイドライン、利用規約のアップデートを常にモニタリングし、柔軟かつ迅速に社内ポリシーを改定していく機敏な姿勢が経営層と実務担当者の双方に求められます。
企業が生成AIの導入に伴うリスクの不確実性を過度に恐れ、技術の導入をためらって波から取り残されることは、技術革新のスピードが激化するグローバル競争において致命的な遅れを意味します。一方で、法的リスクや契約上の責任分担を軽視した無軌道な活用は、企業の屋台骨である知的財産や築き上げてきたブランド価値を一瞬にして根底から揺るがす事態を招きかねません。知財管理の専門家としての見地に基づき、契約条項の厳密な精査、最新技術を用いた防御策の実装、そして継続的な社内教育という三位一体のアプローチを推進することで、企業は生成AIのもたらす圧倒的な恩恵を最大限に享受しながら、持続可能で競争力のある知財収益化のサイクルを実現することができるでしょう。
(この記事はAIを用いて作成しています。)
- WIPO, “Generative AI Factsheet”, https://www.wipo.int/about-ip/en/frontier_technologies/pdf/generative-ai-factsheet.pdf
- Koley Jessen, “AI Contracting Practical Legal Guidance”, https://www.koleyjessen.com/insights/publications/ai-contracting-practical-legal-guidance-for-growing-businesses
- WIPO, “WIPO Lex Text 339521”, https://www.wipo.int/wipolex/en/text/339521
- OpenAI, “Business Terms”, https://openai.com/policies/may-2025-business-terms/
- OpenAI, “Service Terms”, https://openai.com/policies/service-terms/
- Google Cloud, “Protecting customers with generative AI indemnification”, https://cloud.google.com/blog/products/ai-machine-learning/protecting-customers-with-generative-ai-indemnification
- Google Cloud, “Service Terms”, https://cloud.google.com/terms/service-terms
- Legal Dive, “Google to indemnify generative AI users”, https://www.legaldive.com/news/google-indemnify-generativeai-users-against-infringement-copyright-IP-genAI/696593/
- Microsoft, “Customer Copyright Commitment”, https://learn.microsoft.com/en-us/azure/ai-foundry/responsible-ai/openai/customer-copyright-commitment?view=foundry-classic
- WIPO, “Patent Landscape Report on Generative AI”, https://www.wipo.int/web-publications/patent-landscape-report-generative-artificial-intelligence-genai/en/key-findings-and-insights.html
- WIPO, “Artificial Intelligence and Intellectual Property”, https://www.wipo.int/en/web/frontier-technologies/artificial-intelligence/index
- European Parliament, “Report A-10-2026-0019”, https://www.europarl.europa.eu/doceo/document/A-10-2026-0019_EN.html
- 文化庁, “令和5年度 著作権制度に関する調査研究(AIと著作権に関する調査研究)”, https://www.bunka.go.jp/tokei_hakusho_shuppan/tokeichosa/chosakuken/pdf/94035501_04.pdf
- Baker Donelson, “OpenAI Updates Usage Policies”, https://www.bakerdonelson.com/openai-updates-usage-policies-key-considerations-and-next-steps-for-organizations-deploying-ai