生成AIが知的財産法にもたらす激震:著作権、特許、営業秘密の未来

皆様、こんにちは。株式会社IPリッチのライセンス担当です。
生成AI(人工知能)技術は、今やビジネスのあらゆる側面に革命をもたらしています。しかし、この急速な進化は、知的財産(IP)という法律の根幹を揺るがす、重大かつ複雑な課題を突きつけています。
本記事の趣旨は、知的財産の実務家および専門家の皆様に向けて、生成AIがもたらす主要な法的論点を網羅的に解説することです。現在、世界中の法廷や立法府で議論されている核心的な問題は、大きく2つの側面に分けることができます。
第一に「インプット(学習)」の問題です。AIモデルが学習のために著作権で保護された何百万もの記事、画像、音楽を無許諾で使用することは、著作権侵害にあたるのでしょうか。第二に「アウトプット(生成)」の問題です。AIが生成したコンテンツやAIの支援を受けて生み出された発明の「著作者」や「発明者」は一体誰になるのでしょうか。
この記事では、まず『ニューヨーク・タイムズ』紙やゲッティイメージズ、ユニバーサルミュージックグループ(UMG)が起こした大規模訴訟の最新動向を追い、著作権侵害の議論が「訴訟」から「ライセンス」へと移行しつつある現状を分析します。次に、日米欧の規制当局(米国著作権局、日本文化庁、欧州連合)が、「AI生成物の著作権」や「発明者適格性」について、いかに「人間中心主義」の原則を再確認しているかを詳述します。さらに、サムスンの事例に見る「営業秘密」の漏洩リスクと、それを回避するための戦略についても考察します。
結論として、生成AIをめぐる知的財産の法務環境は依然として不安定であるものの、この混乱の中から「データセットのライセンス」や「AI支援発明の特許化」といった、新しい「知財の収益化」モデルが明確に生まれつつあることを示します。
生成AIと著作権(インプット):巨大訴訟とライセンスモデルの胎動
生成AIの知的財産に関する議論で、最も激しい対立を生んでいるのが「学習データ」の問題です。AI開発企業は、インターネットから膨大なテキストや画像を収集(スクレイピング)し、AIモデルの学習に利用してきました 。これに対し、コンテンツ制作者側は、この行為が自らの著作権を大規模に侵害するものだとして、訴訟を提起しています。
主要訴訟の動向:NYTとGetty Images
この対立を象徴するのが、米国の主要な訴訟です。
『ニューヨーク・タイムズ(NYT)』紙は、OpenAIとMicrosoftに対し、同紙の数百万件の記事が著作権を侵害する形でAIモデルの学習に使用されたとして訴訟を起こしました 。NYTの主張の核心は、AIモデルが学習データを単に「学習」するだけでなく、時には記事をほぼそのまま「再生(regurgitate)」し、NYTの有料購読サービスと直接競合する出力を生成している点にあります 。この訴訟は、AIが報道機関のビジネスモデルを根幹から脅かす可能性をはらんでおり、その行方はパブリッシング業界全体に大きな影響を与えるでしょう 。
画像業界では、ストックフォト大手のゲッティイメージズ(Getty Images)が、画像生成AI「Stable Diffusion」の開発元であるStability AIを提訴しました 。ゲッティ側は、1,200万点以上の画像データが無断で学習に使用されたと主張しています 。特に注目すべきは、生成された画像の一部に、ゲッティイメージズの「ウォーターマーク(電子透かし)」が歪んだ形で再現されていた点です 。AIがウォーターマークごと画像を生成したという事実は、「AIの利用は(元の作品とは異なる目的の)変容的利用であり、フェアユースにあたる」というAI開発側の中心的な主張を弱める強力な証拠となり得ます 。
英国での訴訟では、学習行為そのものが英国内で行われたという証拠が不十分だったため、主要な著作権侵害の申し立て(一次侵害)は管轄権の問題で棄却されましたが、二次侵害や商標権侵害に関する論点は依然として残っています 。
転換点:UMG対Udio訴訟とライセンス契約への移行
こうした「訴訟による対立」の構図は、2025年後半に大きな転換点を迎えました。音楽業界の最大手ユニバーサルミュージックグループ(UMG)は当初、AI音楽生成プラットフォームの「Udio」と「Suno」を、自社の楽曲カタログを大規模に侵害したとして提訴していました 。
しかし2025年10月29日、UMGとUdioは訴訟の和解を発表し、同時に戦略的パートナーシップを締結するという驚くべき展開を見せました 。この合意に基づき、Udioは2026年に、UMGの楽曲カタログから正式にライセンス許諾を受けたデータのみを使用して学習させた、全く新しいAI音楽プラットフォームを立ち上げる予定です 。
このモデルの画期的な点は、アーティストが自らの楽曲をAI学習に利用することを明示的に「オプトイン(許諾)」する仕組みであり、さらにアーティストは「学習データとしての利用」と「生成された楽曲の利用」の両方から収益分配(補償)を受けられる点です 。
このUMGとUdioの合意は、AI開発における著作権問題が、法廷闘争からビジネス上の交渉とライセンス契約へと移行する「青写真」を示したものと評価されています 。一方で、同様の訴訟を抱えるUdioの競合「Suno」は、このライセンスの枠組みから外れており、法務リスクの面で不利な立場に立たされています 。今後は、「Fairly Trained」のような、適法にライセンスされたデータのみで学習したことを認証するモデルが、商用利用のスタンダードになる可能性があります 。
生成AIと著作権(アウトプット):誰が「著作者」なのか?
インプット(学習)の問題と並んで重要なのが、アウトプット(生成物)の著作権です。AIが生成した画像、文章、音楽は、法的に誰のものになるのでしょうか。この問いに対し、世界各国の著作権当局は「人間」の創造的寄与を中核に据える伝統的な原則を再確認しています 。
米国著作権局(USCO):「人間の著作者性」の要件
米国著作権局(USCO)は、AIと著作権に関するガイダンスを相次いで発表しています。その基本姿勢は、「著作権保護の適格性を得るためには、作品が人間の著作者(human author)によって創作されている必要がある」というものです 。
2023年、「Zarya of the Dawn」というコミックブックの事例で、USCOはこの原則を具体的に示しました 。作者は、テキストと画像の「選択および配列」については著作権登録を認められましたが、画像生成AI「Midjourney」を使用して作成された画像そのものについては、「人間の著作者性」を欠くとして著作権が否定されました 。作者がAIに指示(プロンプト)を与えただけでは、AIが内部でどのように画像を生成したかを制御できておらず、「創造の主導権(master mind)」を握っているとは言えない、と判断されたためです 。
USCOの2023年3月のガイダンスでは、AI生成物が含まれる作品の著作権を申請する際、申請者はAIによって生成された部分を明示的に「放棄(disclaim)」する義務があるとされました 。
ただしUSCOは、AIを「ツール」として使用することを否定していません。AIが生成した素材に対し、人間が「十分な創造的寄与(sufficient human contribution)」を加えた場合(例えば、AIの出力を大幅に編集・修正したり、複数のAI生成物を独創的に組み合わせたりした場合)、その人間による創造的な部分については著作権が認められるとしており、最終的にはケースバイケースでの判断が続きます 。
日本(文化庁):「思想又は感情の創作的表現」
日本における法解釈も、基本的には米国と同様のアプローチです。2024年3月に文化庁の文化審議会が公表した「AIと著作権に関する考え方について(素案)」では、AIが自律的に生成したものは、人間の「思想又は感情の創作的表現」とは言えず、著作物として認められない可能性が高いとされています 。
一方で、日本のアプローチが興味深いのは、人間が「著作者」と認められる可能性のある具体的な寄与の態様を検討している点です 。例えば、以下のような場合です 。
- AIへの指示(プロンプト)の入力内容や量
- 生成された複数の選択肢からの「選択」行為
- AI生成物に対する人間の「修正・加工(補筆、削除など)」
これらの人間の行為全体に「創作的寄与」が認められれば、最終的な生成物が「著作物」として保護される余地がある、と示されています 。
各国の法整備(TDM例外):米国・EU・日本の比較
AIの学習データ問題を法的にどう扱うかについて、主要国の間ではアプローチが分かれています。特に「テキスト・アンド・データ・マイニング(TDM)」に関する著作権の例外規定が、各国のAI戦略を左右する鍵となっています。
米国:「フェアユース」をめぐる法廷闘争
米国にはTDMに特化した例外規定がなく、AI開発企業は従来の「フェアユース(公正な利用)」の法理に保護を求めています 。フェアユースは、(1)使用の目的と性格、(2)著作物の性質、(3)使用された部分の量と実質性、(4)使用が原著作物の潜在的市場に与える影響、という4つの要素を総合的に考慮して判断されます 。
これは非常に柔軟な規定である一方、予測可能性が低く、裁判所の判断に委ねられる領域が広くなります 。2025年5月、米国著作権局はAI学習に関する報告書(第3部)の草稿を発表し、「AI学習における一部の著作物利用はフェアユースに該当し、一部は該当しないだろう」との見解を示し、ケースバイケースの判断が不可避であることを認めました 。
例えば、作家らが起こした集団訴訟(Bartz v. Anthropic)では、AI企業が「海賊版サイト」から違法に入手した書籍データを学習に使用していたことが明らかになりました 。このような違法な手段で入手したデータに基づく学習が、フェアユースとして認められる可能性は極めて低いと見られています。この訴訟は最終的に、2025年9月に15億ドル規模の和解案が予備承認されています 。
日本:「非享受」目的を許容する著作権法30条の4
日本は、2018年の著作権法改正で導入された第30条の4により、世界で最もAI開発に有利な国のひとつと見なされてきました 。この条文は、著作物に表現された思想・感情の「享受」を目的としない利用(=非享受目的)、具体的には「情報解析」のための利用であれば、原則として著作権者の許諾なく利用できると定めています 。AIの学習データ作成は、この「情報解析」にあたるというのが一般的な解釈でした 。
しかし、この「AI天国」とも呼ばれた解釈には、2024年に文化庁がブレーキをかけました。文化庁の見解では、たとえ非享受目的であっても「著作権者の利益を不当に害することとなる場合」は例外の対象とならない、と明確化されました 。具体的には、特定のクリエイターの画風や作風を模倣するAIを開発するために、そのクリエイターの作品のみを集中的に学習させる(ファインチューニングする)ような行為は、元の作品の市場と競合し、利益を不当に害するとして、30条の4の適用外となる可能性が高いと示されました 。
欧州連合(EU):「オプトアウト」と「透明性義務」の規制
EUは、米国と日本の「中間」とも言える、規制に基づいたアプローチを採用しています。2019年の「デジタル単一市場における著作権指令(CDSM指令)」の第4条は、商業目的のTDM利用を認めつつも、著作権者が「機械可読な方式」などで利用を「留保(オプトアウト)」する権利を保障しました 。
さらに、2024年に成立した包括的な「EU AI法」は、この著作権の枠組みをAI開発者に強制するものとなっています 。AI法第53条は、汎用AIモデル(GPAI)の提供者に対し、以下の2点を義務付けました 。
- EUの著作権法(特にCDSM指令第4条のオプトアウト)を尊重するための方針を整備・実行すること 。
- AIモデルの学習に使用したコンテンツの「十分に詳細な概要」を作成し、公表すること 。
この「透明性義務」は、著作権者が自らの作品が学習に使用されたか否かを確認し、オプトアウトの権利を行使するための前提となるものです 。
しかし、このEUの枠組みに対しても、すでに批判が出ています。2025年7月に欧州議会が発表した調査研究では、現行のTDM例外規定は、そもそも生成AIの大規模学習を想定して設計されておらず不十分であると結論付けられました 。同研究は、現状の「オプトアウト」方式(原則自由、禁止は権利者が表明)から、より権利者保護に手厚い「オプトイン」方式(原則禁止、利用は権利者の許諾が必要)への移行を含めた、抜本的な法改正を求めています 。
生成AIと特許:「発明者」は人間かAIか
著作権がインプットとアウトプットの両方で問題を抱える一方、特許法における最大の論点は「発明者適格性」です。すなわち、「AIは発明者になれるのか?」という問いです。
DABUS訴訟と世界の司法判断
この問題を世界的に提起したのは、スティーブン・セーラー博士が開発したAI「DABUS」です 。セーラー博士は、DABUSが自律的に2つの発明(食品容器と警告灯)を生み出したとして、DABUS自身を「発明者」として各国(米国、英国、欧州、日本など)で特許出願を行いました。
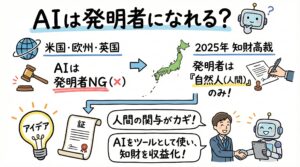
この試みに対する各国の司法・行政判断は、ほぼ満場一致で「否」でした 。
2023年12月、英国最高裁判所は、英国特許法(1977年法)における「発明者」とは、法的に「自然人(natural person)」、すなわち人間に限定されると判示しました 。セーラー博士は「DABUSの所有者である自分に発明の権利が帰属する」とも主張しましたが、裁判所は「発明の権利は、発明者(人間)から発生するものであり、発明を生み出した機械の所有権から自動的に発生するものではない」として、この主張も退けました 。
日本においても、2024年5月に東京地方裁判所がDABUSの出願を「発明者は人間に限られる」として特許庁の拒絶査定を支持する判決を下しています 。
米国特許商標庁(USPTO):「AI支援発明」の特許適格性
DABUS訴訟が示したのは、「AI のみ が発明者である発明」は特許化できない、という点です。では、「AIの 支援を受けて 人間が行った発明」はどうなるのでしょうか。
この実務上最も重要な問いに対し、米国特許商標庁(USPTO)が2024年2月に明確なガイダンスを発表しました 。
USPTOは、AIは発明者にはなれないと確認しつつも、「AI支援発明(AI-assisted inventions)」は特許保護の対象外ではないと明言しました 。特許が認められるための鍵は、発明の着想(conception)に対して「人間が重要な貢献(significant contribution)をしたか」どうかです 。
この「重要な貢献」があったか否かは、従来の共同発明者に関する判例(Pannu v. Iolab Corp.)の基準に基づいて判断されます 。具体的には、単にAIを所有・運用していただけ、あるいはAIに一般的なプロンプトを与えただけでは「発明者」とは認められません 。しかし、人間がAIの出力を基に特定の設計を選択したり、AIの出力を改良して予期せぬ結果を達成したりした場合、その人間は「重要な貢献」をした発明者として認められる可能性が高くなります。このガイダンスは、AIをイノベーションのツールとして活用する企業にとって、特許戦略の指針となるものです 。
生成AIと営業秘密:サムスン事件に学ぶ漏洩リスク
著作権や特許が「権利の発生」をめぐる問題であるのに対し、営業秘密(トレードシークレット)の文脈では、AIは「権利の喪失」という深刻なリスクをもたらします。
営業秘密とは、有用な技術情報や顧客リストなど、「秘密として管理」されており、「秘密であることによって経済的価値を持つ」情報です 。法的な保護を受ける大前提は、企業がその秘密性を維持するために「合理的な措置(reasonable measures)」を講じていることです 。
生成AI、特に一般に公開されているLLM(大規模言語モデル)の利用は、この「秘密性」を根本から破壊する危険をはらみます 。従業員が、機密情報や社外秘のデータをAIチャットボットに要約させたり、ソースコードのデバッグをさせたりするために安易に入力した場合、そのデータはAI開発企業のサーバーに送信され、AIモデルのさらなる学習に使用される可能性があります 。
サムスン電子の機密情報漏洩インシデント
このリスクが現実化したのが、サムスン電子で発生したインシデントです 。報道によれば、同社のエンジニアが機密性の高いソースコードや社内会議の議事録をChatGPTに入力し、コードの最適化や議事録の要約を試みました 。ChatGPTの利用規約(当時)では、入力されたデータがモデルの学習に使用される可能性があるとされており、一度送信された機密情報を回収することは不可能です 。
この行為は、企業が「合理的な措置」を怠ったとみなされ、万が一その情報が競合他社に知られた場合、営業秘密としての法的保護を主張できなくなる致命的な結果を招きます 。
対策:AI保護手段としての営業秘密
このリスクへの対策として、企業は厳格な「AI利用ポリシー」を策定し、従業員教育を徹底することが不可欠です 。また、機密情報を扱う場合は、外部の公開AIサービスを禁止し、情報が外部に送信されない「オンプレミス型(自社サーバー設置型)」やプライベートなAIソリューションを導入する必要があります 。
一方で、このリスクは逆説的に、AIモデルそのものを保護するための新たな戦略を示唆しています。AIモデルのアーキテクチャや学習済みモデル(重み)は、特許として公開すると模倣されやすくなるため、あえて特許出願せず、「営業秘密」として厳格に管理する戦略が主流になりつつあります 。
生成AI時代における「知財の収益化」の新潮流
生成AIがもたらすのは、法的リスクだけではありません。知的財産の専門家にとって、これは「知財の収益化」戦略を根本から見直す好機でもあります 。
第一に、AIは特許収益化の「ツール」として極めて強力です。AIを利用することで、自社の広範な特許ポートフォリオを瞬時に分析し、市場ニーズと照合してライセンス供与すべき有望な特許を特定したり、潜在的なライセンス交渉先をリストアップしたりすることが可能になります 。
第二に、AI支援発明の特許化です。前述のUSPTOガイダンス に見られるように、「人間による重要な貢献」を立証することでAI支援発明の特許を取得し、これをライセンス供与や売却の対象とする道が明確になりました 。
第三に、最も大きな変化は「データライセンス市場」の創出です。UMGとUdioの歴史的な和解 や、EU AI法の透明性義務 は、「無断でデータを収集(スクレイピング)する時代」の終わりと、「許諾を得てデータを利用(ライセンシング)する時代」の幕開けを告げています。出版社や報道機関、音楽レーベル、ストックフォト企業にとって、自社が保有する高品質なデータセットは、AI開発企業に対する新たなライセンス収益の源泉となり得ます 。
第四に、企業はAI自体を製品やサービスに組み込むことで、新たな収益源を生み出しています。例えば、通信事業者がAIによる通話の自動要約サービスを有料提供したり、自動車メーカーがAI搭載の高度運転支援システムをサブスクリプション・サービスとして提供したりする事例がすでに見られます 。
このように、生成AIは知的財産法の枠組みを揺るがすと同時に、知的財産の価値を再定義し、その収益化のあり方を多様化させています。法務リスクを適切に管理しつつ、これらの新しい収益化の潮流を捉えることが、これからの企業戦略において不可欠となるでしょう。
貴社が保有する特許、特に活用されていない「休眠特許」の収益化に関心をお持ちではありませんか。生成AI時代には、従来の枠組みでは評価されにくかった特許技術が、思わぬ形で価値を生む可能性があります。
特許売買・ライセンスプラットフォーム「PatentRevenue」は、貴社の貴重な知的財産を収益に変えるお手伝いをいたします。PatentRevenueに特許情報を無料で登録し、新たなビジネスチャンスを探ってみませんか。
ご登録はこちらから: https://patent-revenue.iprich.jp
(この記事はAIを用いて作成しています。)