オープンソースシールドの神話:AIモデル利用のライセンス遵守と知財リスク管理の最前線
株式会社IPリッチのライセンス担当です。本日は、昨今急速に普及している生成AIを活用したソフトウェア開発において、多くの開発者や企業が陥りがちな「オープンソースシールドの神話」という重大な問題について詳しく解説いたします。オープンソースの学習モデルやAIコーディングアシスタントを利用すれば、元のコードに付随するライセンス義務から免れられると勘違いするケースが後を絶ちません。しかし実際には、生成AIが出力するコードにはオープンソースソフトウェア(OSS)由来の成分がそのまま含まれている可能性が非常に高く、複製や派生物への条件、さらには商用利用の制限といった下流のライセンス義務を厳格に確認する仕組みが不可欠です。本記事では、最新の著作権訴訟の動向から、企業が取るべきコンプライアンス体制、そして開発現場に求められる技術的解決策まで、法務と技術の両面から網羅的かつ専門的に解説します。
企業が激しい市場競争を勝ち抜き、持続的な成長を遂げるためには、開発したソフトウェアや技術資産を適切に保護し、そこから利益を生み出す「知財の収益化」という戦略が極めて重要になります。しかし、AI生成コードの利用に潜むオープンソースのライセンス違反リスクは、この知財の収益化プロセスを根底から脅かし、企業のコア技術の価値を著しく毀損する危険性を孕んでいます。複雑化するAI時代の知財リスクを的確に管理し、攻めの収益化戦略を社内で牽引するためには、高度な専門知識と強固なコンプライアンス意識を備えた人材の確保が急務となっています。知財人材を採用したい事業者に向けて、知財特化型スカウトサービスである「PatentRevenue」で求人情報を無料で登録することを強く推奨いたします。詳細な情報やご登録については、 https://patent-revenue.iprich.jp/recruite/ をご参照ください。適切な知財専門人材の確保と強固な体制構築こそが、企業の知財価値を最大化し、ビジネスを成功に導くための鍵となります。
1.生成AIモデルの学習データとオープンソースライセンスの複雑な関係性
近年、ソフトウェア開発の現場において、生成AIを活用した高度なコーディングアシスタント機能が爆発的な普及を見せています。これらのAIツールは、数行のプロンプトから複雑なアルゴリズムや定型的なコードブロックを瞬時に提案し、開発者の生産性を飛躍的に高める革新的な存在となっています。しかし、その利便性の裏側には、知的財産権やライセンスに関する極めて複雑な課題が潜んでいます。AIモデルが自然なコードを生成できるのは、インターネット上に公開されている数十億行にも及ぶ膨大なソースコードを学習データとして取り込んでいるからです。そして、それらの公開コードの大半は、無条件に利用できるわけではなく、特定の「オープンソースライセンス」の制約のもとで提供されています。
オープンソースライセンスには、利用や改変、再配布に関する明確な法的ルールが定められており、ソフトウェアの利用者はこれらの条件を厳格に遵守する義務を負います。特に注意が必要なのが、GNU General Public License(GPL)などに代表される「コピーレフトライセンス」と呼ばれる形態です。コピーレフトライセンスは、そのライセンスが付与されたコードを利用、改変、または組み込んで作成された「派生物(Derivative Works)」に対しても、元のコードと全く同じライセンス条件を適用することを強く要求します。これは実務上、自社の非公開(プロプライエタリ)な商用ソフトウェアにコピーレフトライセンスのコードの断片を組み込んでしまった場合、ソフトウェア全体のソースコードを第三者に向けて公開しなければならないという、企業にとって致命的なリスク(いわゆるライセンスの汚染)が生じることを意味します。
一方で、MITライセンスやApacheライセンスなどに代表される「パーミッシブ(寛容型)ライセンス」は、改変したコードを非公開のまま商用利用することを許容しており、比較的制限が緩いとされています。しかし、制限が緩いとはいえ決して無条件ではありません。パーミッシブライセンスであっても、元の開発者の著作権表示やライセンス条項のテキストを、ソフトウェアの再配布時に必ず含めなければならないという最低限の法的義務が課されています。生成AIを利用してソフトウェアを開発する企業は、AIが出力するコードの背後にこうした多種多様なライセンスの仕組みが横たわっていることを正しく理解し、法的トラブルを未然に防ぐための第一歩を踏み出す必要があります。
2.開発現場に蔓延する「オープンソースシールドの神話」という危険な誤解
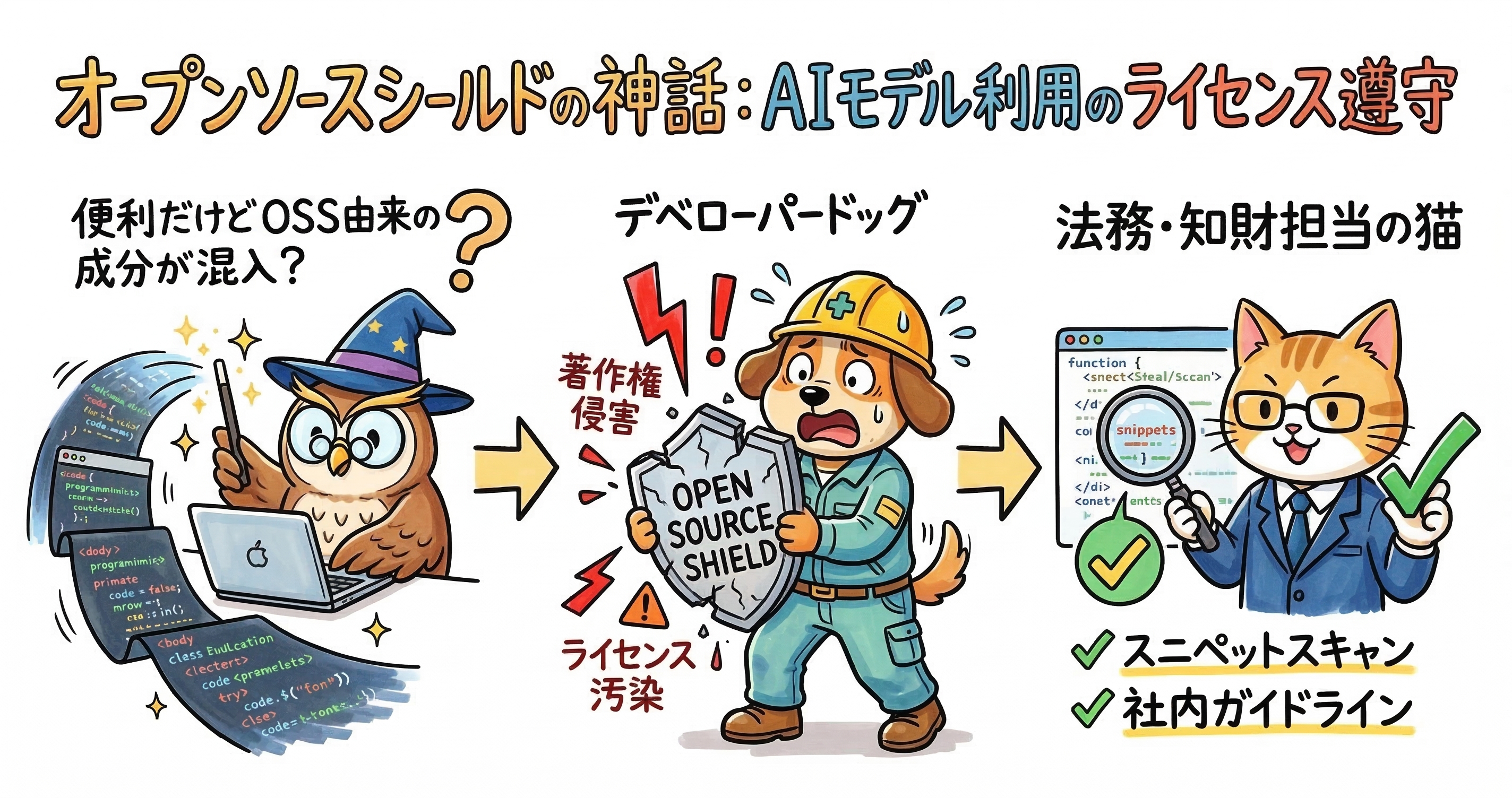
AI技術の急速な進化と普及に伴い、世界中のソフトウェア開発現場で急速に広まっている危険な認識があります。それが本稿の主題でもある「オープンソースシールドの神話」です。驚くべきことに、多くの開発者は、AIという高度で不可解なアルゴリズムの層を経由して生成されたコードは「機械が新たに書き下ろした完全なオリジナル作品」であり、元の学習データが持っていたオープンソースライセンスの法的な義務からは完全に免除されると信じ込んでいます。あたかも生成AIの存在が、既存のソースコードの法的制約を全て洗い流し、クリーンな状態にしてくれる「シールド(盾)」として機能するかのように錯覚しているのです。
しかし、法的な観点や技術の実態から見れば、これは非常に危うく誤った認識と言わざるを得ません。実際には、生成AIが提示するコードスニペットが、学習データとして取り込まれたオープンソース由来の成分をそのまま、あるいは極めて似た形で含んでいる可能性は十分にあります。AI開発ベンダーは、モデルが元のコードを丸暗記してそのまま出力してしまう「Regurgitation(吐き出し・暗唱)」現象は確率的には非常に稀であると主張しています。しかしながら、実際の開発現場や研究者の検証においては、特定のプロンプトの入力や条件が重なった場合に、元のオープンソースコードの変数名、独自のロジック、さらには開発者が書き残したコメント文まで一言一句違わずにAIが再現してしまう事例が多数報告されています。
AIが出力したこのようなコードを、その出処を確認せずにそのまま自社の製品に組み込んでしまった場合、開発者は無自覚のうちに他者の著作物を無断で複製していることになります。AIというツールを利用したからといって、オープンソースライセンスが課している「帰属表示の義務」や「派生物の公開義務」が魔法のように消滅するわけではありません。むしろ、AIというブラックボックスを経由することによって、どのコードが誰の著作物であり、どのようなライセンス条件に紐づいているのかというトレーサビリティ(追跡可能性)が完全に失われてしまう点に問題の本質があります。コンプライアンス違反のリスクが巧妙に隠蔽され、気づかぬうちにライセンス汚染が進行してしまうことこそが、このオープンソースシールドの神話がもたらす最大の脅威なのです。
3.ライセンス遵守と著作権侵害リスクを問うGitHub Copilot集団訴訟の衝撃
AI生成コードとオープンソースライセンスを巡る複雑な法的課題は、もはや理論上の懸念にとどまらず、すでに現実の激しい法廷闘争へと発展しています。その行方を世界中のIT企業が固唾を呑んで見守っているのが、AIコーディングアシスタントの先駆者である「GitHub Copilot」およびその基盤となるAIモデル「Codex」を提供するGitHub、Microsoft、OpenAIに対する大規模な集団訴訟です。この歴史的な訴訟は、プログラマーであり法律家でもあるマシュー・バターリック氏と、専門の法律事務所チームによって提起され、AIモデルの学習プロセスとコードの出力プロセスの両面において、オープンソース開発者の知的財産権が深刻に侵害されていると強く非難しています。
原告側の主張の核心は、GitHub Copilotが数千万のリポジトリと数十億行に及ぶ公開コードから学習する過程において、オープンソースライセンスに付随する法的・倫理的な義務を組織的かつ意図的に無視しているという点にあります。特に法廷で問題視されているのが、米国のデジタルミレニアム著作権法(DMCA)の違反と、ライセンス規約に基づく契約不履行の二点です。原告は、Copilotがユーザーのプロンプトに応じてコードを出力する際、元のソースコードに本来付与されていた著者名、著作権表示、ライセンスの適用条件といった「著作権管理情報(CMI)」を機械的に剥ぎ取って(あるいは改ざんして)提示していると指摘しています。これは、コードを利用する条件として適切な帰属表示を求めているほぼ全てのオープンソースライセンスの基本原則に対する、明確な契約違反行為であると主張されています。
これに対して、AIモデルを開発・提供する企業側は、主に「フェアユース(公正利用)」の法理を盾にして防御を展開しています。インターネット上の公開データを収集し、それを解析してAIモデルという新しいシステムを構築する行為は、元のコードの代替品を作るものではなく、全く新しい価値を生み出す「変容的(Transformative)な利用」に該当するため、著作権の侵害には当たらないという論理です。
しかしながら、ソフトウェアを開発・提供するエンドユーザー企業にとってより深刻かつ直視すべき現実は、サービス利用規約の中に潜む「責任の所在」です。MicrosoftをはじめとするAIベンダーは、AIが出力するコードの正確性やセキュリティの安全性、さらにはそれが第三者の知的財産権を侵害していないことについて、一切の法的保証を行っていません。規約上、出力されたコードを利用前のIPスキャン(知財調査)やセキュリティ確認を行う責任は、すべてサービスを利用する開発者側に委ねられています。つまり、万が一AIの提案コードが他社のオープンソースライセンスを侵害していた場合、その矢面に立たされ、損害賠償やコード公開の責任を負うのはAIベンダーではなく、ツールを利用してソフトウェアを開発した企業自身であるという厳しい事実を認識しなければなりません。
4.知財の収益化を厳しく審査するベンチャーキャピタルからの視線
オープンソースライセンスのコンプライアンス違反は、単に法務部門が対応すべき法的なペナルティの問題にとどまりません。それは、企業の競争力の源泉を揺るがし、経営戦略や企業価値に直結する極めて重大なビジネスリスクです。特に、革新的な技術を武器に新規事業の立ち上げや多額の資金調達、あるいは将来的なM&A(合併・買収)によるエグジットを見据えているスタートアップやテクノロジー企業にとって、自社で開発しているソフトウェア内部のライセンスの健全性は、「知財の収益化」を実現し、企業価値を最大化するための絶対的な前提条件となります。この点に関して、投資家やベンチャーキャピタル(VC)は、かつてないほど厳格な視線を注いでいます。
この厳格な審査基準を象徴しているのが、全米ベンチャーキャピタル協会(NVCA)が公式に提供している投資契約書のモデル文書です。NVCAの株式投資契約の雛形には、「表明保証(Representations and Warranties)」と呼ばれるセクションがあり、そこには対象企業がオープンソースソフトウェアをどのように利用し、管理しているかに関する詳細な法的宣言が組み込まれています。具体的には、出資を受ける企業に対し、「自社のプロプライエタリな知的財産(ソースコード)を公開したり、無償で配布したり、派生物の作成を他者に許可しなければならないような方法で、コピーレフトライセンスのコードを使用していないこと」を宣誓させ、法的な拘束力を持たせています。
もし、投資に向けた詳細な技術デューデリジェンス(資産査定)の過程で、開発チームが生成AIの利便性に頼るあまり、無自覚にGPLなどの強力なコピーレフトコードを自社の基幹システムや主力製品に混入させていることが発覚した場合、その影響は壊滅的です。投資家は、その企業の最大の武器であるはずの「独自の知財(Core IP)」が、ライセンスの波及効果によって将来的にオープンソース化を強要される状態にあると判断します。その結果、巨額の資金調達の交渉が土壇場で白紙撤回されたり、企業価値の評価額(バリュエーション)が大幅にディスカウントされたりする事態が実際に頻発しています。
最悪のシナリオでは、法的リスクを回避し投資を成立させるために、汚染されたオープンソースコードをシステムから完全に排除し、機能の再構築(リファクタリング)を行うための莫大な時間とコストを余儀なくされます。オープンソースのコンプライアンスは、知財弁護士が指摘するように、「病院の衛生管理」に似た性質を持っています。一度検査をして終わりではなく、日々の開発プロセスの中で継続的かつ徹底的に監視・管理されなければならないプロセスなのです。AIを全社的に導入する企業は、知財の収益化を根底から崩壊させるこのようなビジネス上の致命傷を避けるため、経営トップの主導により、開発の初期段階から厳密なライセンス管理体制を構築しなければなりません。
5.日本国内におけるAI生成コードの著作権法解釈と企業ガイドライン
AIが生成したコードに関する知的財産権のリスクは、アメリカを中心とした海外だけの問題ではありません。日本国内においても、生成AIの業務利用が爆発的に拡大する中、著作権法をはじめとする国内の法的枠組みに基づいた精緻なリスク評価と、実務に即した企業向けガイドラインの策定が急務とされています。日本企業が生成AIを利用したソフトウェア開発を行う際、開発者や法務担当者は国内法の独自の解釈基準を正確に理解しておく必要があります。
日本の著作権法実務においては、生成AIに関連する権利侵害のリスクは、主にAIモデルを作り上げる「学習・開発段階」と、ユーザーがAIを利用してコンテンツを出力する「生成・利用段階」の二つの局面に明確に分けて議論されます。学習段階においては、著作権法第30条の4の規定により、情報解析を目的とする場合は原則として他人の著作物を許諾なく利用することが認められており、比較的柔軟な運用がなされています。しかし、ソフトウェア開発の現場において直接的かつ深刻な法的リスクとなるのは、後者の「生成・利用段階」における著作権侵害です。
AIが生成したコードが既存の第三者の権利を侵害しているかどうかの法的な判断は、人間の創作活動における基準と全く同様に、「類似性」と「依拠性」という二つの要件を満たすかどうかによって決まります。類似性とは、AIが生成したコードの表現が、既存のオープンソースコードなどと実質的に同一、あるいは極めて似ていることを指します。問題となるのは「依拠性」の証明です。依拠性とは、既存のコードの存在を知った上で、それを元にして作成したことを意味します。開発者自身が元のコードを知らなくても、利用しているAIモデルが当該のオープンソースコードを学習データとして取り込んでいる事実があり、かつAIの出力をそのまま利用した場合には、法的に依拠性が推認され、結果として著作権侵害が成立するリスクが跳ね上がります。
こうした国内法特有のリスクを最小限に抑え、安全な開発環境を維持するためには、企業は従業員に対する明確で実効性のある「生成AI利用ガイドライン」を社内に整備し、運用を徹底する必要があります。例えば、東京都などの行政機関が示しているガイドラインの雛形は、一般企業にとっても非常に優れた参照モデルとなります。このガイドラインでは、AIに入力する情報(プロンプト)の機密性をレベル分けし、取り扱いを厳格に規定することが推奨されています。
個人情報や未公開の基幹システムの設計図、他社から秘密保持義務を負って預かっているデータなど、「機密性A」に該当する高度な秘密情報は、AIの学習に利用されることによる情報漏洩や他者の権利侵害を防ぐため、いかなる場合もプロンプトへの入力が固く禁じられなければなりません。また、生成AIが出力したコードを利用する際には、それがオープンソースのライセンス違反を引き起こしていないか、あるいは既存の権利を侵害していないかを、ツール任せにするのではなく人間が必ず最終確認を行うという運用ルールの徹底が、国内のコンプライアンス管理において強く求められています。
6.開発現場で実践すべき高度な技術的解決策とスニペットスキャニングの進化
法務部門が主導して詳細なガイドラインや社内ルールを整備することは極めて重要ですが、それだけでは現代の目まぐるしいアジャイル開発のスピードに追随して知財リスクを完全に排除することは事実上不可能です。生成AIはわずか数秒の間に数十行から数百行に及ぶコードブロックを提案します。その膨大なAI生成コードの中から、たった数行紛れ込んだGPLライセンス由来のコードを、開発者が目視で逐一確認し特定することは非現実的です。したがって、開発現場においては、ライセンス遵守のための確認作業を自動化し、開発者の日々のワークフローにシームレスに統合する「技術的解決策」が絶対に欠かせません。
この領域で現在最も注目を集め、技術的な進化を遂げているのが、高度な「スニペットスキャニング(Snippet Scanning)」技術です。コードの一部(スニペット)をスキャンして出処を確認するツール自体は、AIブーム以前から存在していました。かつての世代のスキャンツールは、Stack Overflowなどの公開フォーラムから開発者が手動でコピー&ペーストしたコードを検出することを主な目的としていましたが、類似した一般的なコードにまで反応してしまう誤検知(フォールス・ポジティブ)が極めて多く、手動での確認作業が膨大になり、結果として開発者の生産性を著しく低下させるという大きな課題を抱えていました。
しかし、生成AIがコード生成の主力となりつつある現在、FOSSA社などが提供する次世代のスニペットスキャニングソリューションは、AI特有のリスクに焦点を当てて劇的な進化を遂げています。最新のスキャンエンジンは、AIが元の学習データをそのまま「丸暗記(Regurgitation)」して出力した特異なコードパターンを極めて高い精度で瞬時に検出し、そのコードが元々どのようなオープンソースプロジェクトに属し、いかなるライセンス条件のもとで公開されていたかを自動的に判別する強力な能力を備えています。
この技術により、開発者はAIコーディングアシスタントがもたらす圧倒的な開発ベロシティ(速度)を損なうことなく、バックグラウンドで常にライセンスの健全性を監視させることができます。もしAIが提案したコードにコピーレフトライセンスの成分が含まれていた場合、IDE(統合開発環境)の画面上で即座に警告が表示され、ライセンス汚染のリスクを知らせてくれます。このような高度な技術的セーフティネットをCI/CD(継続的インテグレーション/継続的デリバリー)パイプラインの深部に組み込むことは、意図しないライセンス義務の発生を未然に防ぎ、企業が安心してAI主導のイノベーションを推進するための必須のインフラストラクチャとなっています。
7.セキュアなAIコーディングを実現する先進的なコード検証手法
AIモデルを活用したソフトウェア開発において、オープンソースライセンスのコンプライアンスと並んで決して見逃してはならないのが、コードのセキュリティ品質と脆弱性管理という課題です。AIモデルは、過去に書かれた膨大かつ玉石混交のソースコードから学習しているため、古く非推奨となったコーディング規約に基づいた安全でないロジックや、既知のセキュリティ脆弱性を含んだままのコードを、悪意なく「最適な正解」として提案してしまう危険性を常に孕んでいます。このようなAI特有のセキュリティリスクに対処するため、開発現場ではコードの品質と安全性を自動的に担保する先進的な検証ツールの導入が急速に進んでいます。
最先端の静的アプリケーション・セキュリティ・テスト(SAST)ツール、例えばSnyk社が提供する「DeepCode AI」などは、単一の汎用的な大規模言語モデル(LLM)に依存するのではなく、複数の技術を統合した「ハイブリッドAI」という高度なアプローチを採用しています。この手法は、コードの構造や意味を論理的に解釈するシンボリックAI技術と、柔軟な推論を可能にする生成AI、さらにセキュリティ専門家によるキュレーションデータを組み合わせることで、汎用AIが陥りがちなハルシネーション(もっともらしい嘘の提案)を徹底的に排除し、コードのデータの流れを正確に解析して脆弱性をピンポイントで特定します。
さらに注目すべきは、AIを活用した検証ツール自体のデータの取り扱いです。強固なセキュリティとコンプライアンスを重視するソリューションは、自社の分析エンジンを顧客のセルフホスト環境で稼働させる設計を採用しています。これにより、企業が入力したプロプライエタリなソースコードのデータが、外部のAIモデルの再学習に利用されることを構造的に防ぎ、強力なデータプライバシーと知財保護を実現しています。また、これらの検証ツールは単に問題を指摘するだけでなく、脆弱性が実際に悪用可能であるか(到達可能性)や、該当するパッケージの重要度など、コードの文脈(コンテキスト)を深く理解してリスクの優先順位を自動的に評価します。開発者は、AIが提案する安全でライセンス的にもクリーンな修正コード(オートフィックス機能)をワンクリックで適用できるため、開発の手を止めることなく、極めて高いレベルでセキュリティを担保することが可能になります。
同時に、これらのツールを活用する開発者自身が実践すべき「プロンプトエンジニアリング」のベストプラクティスも確立されつつあります。AIに対して漠然とした抽象的な指示を出すのではなく、具体的な入力例や出力例、さらにはエラー処理などのエッジケースを明示し、自社のシステムアーキテクチャ全体との整合性を意識させる制約を設けることが推奨されています。このようにプロンプトに「具体性(Concrete)」を持たせることで、AIが不要な外部のオープンソースコードを無作為に参照することを抑制し、セキュアで要件に厳密に合致したクリーンなロジックの生成を効果的に誘導することができます。
8.おわりに:オープンソースの恩恵とコンプライアンスの未来
「AIが生成したコードなのだから、その出処は問われないだろう」というオープンソースシールドの神話に警鐘を鳴らすことは、決してAIコーディングアシスタントの利用を禁止したり、オープンソースコミュニティが築き上げてきた知識の共有文化を否定したりするものではありません。むしろ、その逆です。オープンソースは現代のソフトウェア開発エコシステムを根底から支える不可欠な基盤であり、生成AIはその蓄積された知見を何倍にも増幅させ、開発者に届ける画期的なインターフェースです。重要なのは、AIという新しい技術レイヤーが介入したことによって生じた、ライセンスと知的財産権の新たな複雑さを真正面から直視し、適切なガバナンス体制を組織全体で敷くことです。
開発現場においては、AIモデルを利用する際に生じる下流のライセンス義務を正確に把握し、複製や派生物に関する条件をクリアにする仕組みが不可欠です。法務・コンプライアンス部門による明確な社内ガイドラインの策定、開発者に対する依拠性やセキュリティに関する継続的な教育、そして先進的なハイブリッドAIを駆使したスニペットスキャニングやコード検証ツールのワークフローへの統合。これら「ルール」「人」「ツール」の三位一体の対策を講じることで、企業は初めて、AIに潜む知財リスクを完全にコントロールできるようになります。
オープンソースコミュニティの恩恵を最大限に引き出しつつ、自社の貴重な知的財産を確実に保護し、ビジネス上の収益化へとつなげる。この高度で繊細なバランスをAI時代において確立し維持することこそが、次世代のソフトウェアビジネスにおいて真の競争優位性を生み出し、企業が持続可能な成長を遂げるための唯一かつ確実な道筋と言えるでしょう。
(この記事はAIを用いて作成しています。)
1 Analyzing Legal Implications of GitHub Copilot https://fossa.com/blog/analyzing-legal-implications-github-copilot/ 2 GitHub Copilot Intellectual Property Litigation https://www.saverilawfirm.com/our-cases/github-copilot-intellectual-property-litigation 3 GitHub Copilot Investigation https://githubcopilotinvestigation.com/# 4 Insights From the Pending Copilot Class Action Lawsuit https://www.finnegan.com/en/insights/articles/insights-from-the-pending-copilot-class-action-lawsuit.html 5 Discussion GitHub Copilot Litigation Highlights https://www.reddit.com/r/programming/comments/1qhqj5k/discussion_github_copilot_litigation_highlights/ 6 The Copilot Litigation https://www.bakerlaw.com/the-copilot-litigation/ 7 Generative AI Copyright Risk https://exawizards.com/column/article/ai/generative-ai-copyright-risk/ 8 Generative AI Development Guidelines https://levtech.jp/media/article/column/detail_372/ 9 AI Coding Tool Risks: FOSSA Snippet Scanning https://fossa.com/blog/ai-coding-tool-risks-fossa-snippet-scanning/ 10 Snyk DeepCode AI https://snyk.io/platform/deepcode-ai/ 11 Code Scanning https://snyk.io/articles/code-review/code-scanning/ 12 AI-driven Development Sponto 2026 https://sponto.co.jp/insights/ai-driven-development-sponto-2026 13 All About Copyleft Licenses https://fossa.com/blog/all-about-copyleft-licenses/ 14 Copyleft Licenses and Venture Capital Connection https://fossa.com/blog/copyleft-licenses-venture-capital-connection/
関連記事
-
 AIが強化する先行技術調査:セクション102・103拒絶のハードル上昇に備える
AIが強化する先行技術調査:セクション102・103拒絶のハードル上昇に備える -
AI活用による特許審査の進化:Search AI・DesignVision・SCOUTの実務インパクト
-
AIによる「大量先取りデザイン」の懸念と意匠制度の変革:製造業が直面する知財リスクと戦略的対応
-
AI生成物における著作権侵害の回避と企業ガバナンス:二次的侵害を防ぐための実務的審査体制の構築
-
社内AIガバナンスの構築:組織横断チームによるポリシー整備と実践的活用ガイド
-
英国Getty Images対Stability AI訴訟から読み解く生成AI時代の知的財産権:商標権侵害と著作権の境界線
-
【2026年最新】生成AI活用における著作権侵害リスクと社内ガイドライン・チェック体制構築の完全実務解説
-
生成AIのビジネス活用における知的財産権の帰属と知財収益化への実践的アプローチ