AIが生成したコードにもライセンス義務?オープンソース問題と企業の法的リスク対策
株式会社IPリッチのライセンス担当です。昨今、ソフトウェア開発の現場において、生成AIを活用したコーディング支援ツールの導入が急速に進んでいます。開発の生産性を劇的に向上させる強力なツールである一方、生成AIが出力したプログラムコードにオープンソースソフトウェアのコード片が混在し、開発者が意図せず厳格なライセンス義務を負ってしまうという深刻な問題が浮上しています。本記事では、AI生成コードに潜む著作権やライセンス違反の法的リスク、最新の訴訟動向、日本の著作権法における解釈、そして企業が知財を守るために導入すべきコンプライアンス管理や専門ツールの活用戦略について、詳細かつ網羅的に解説いたします。AIツールを安全に活用し、自社のソフトウェア資産を守るための知識として、ぜひお役立てください。
現代のビジネスにおいて、自社で開発したソフトウェアや特許技術を適切に保護し、管理することは、「知財の収益化」を成功させるための重要な鍵となります。どれほど優れたソフトウェアであっても、AIを活用して効率的に生み出されたプログラムの中に、第三者のオープンソースライセンス要件に違反するコードが含まれており、権利侵害を引き起こしていれば、そのソフトウェアの財産的価値は著しく毀損されてしまいます。クリーンで権利関係が明確な知的財産を構築してこそ、他社への安全なライセンス提供や売買を通じた確実な収益化が可能になります。自社で保有する特許権の売買やライセンス供与によって知財の収益化を目指す企業様や担当者様は、ぜひ特許売買・ライセンスプラットフォーム「PatentRevenue」にて、特許権の売買又はライセンスの希望者として無料でご登録いただくことをお勧めいたします。詳細につきましては、PatentRevenueのURL「 https://patent-revenue.iprich.jp/#licence 」をご確認いただき、貴社の安全かつ戦略的な知財ビジネスにお役立てください。
1. オープンソースソフトウェアと著作権法に基づくライセンスの基本構造
オープンソースソフトウェア(以下、OSS)は、現代のソフトウェア開発において欠かせない基盤となっています。しかし、OSSは決して著作権を完全に放棄したパブリックドメイン(公共の財産)ではありません。OSSライセンスとは、開発者である著作者が自身の著作物であるプログラムに対して、特定の利用条件を遵守することを大前提として、第三者への複製や再頒布を許諾するという法的な宣言に他なりません。日本の著作権法第十条第一項第九号において、コンピュータを機能させるプログラムは「プログラムの著作物」として明示的に法的保護の対象となっており、特許権のような煩雑な登録手続きを経ずとも、創作された時点で自動的に著作者に著作権が発生します。したがって、著作者から事前の許可を得ることなく、あるいは許可の条件を満たさずにプログラムを利用、改変、または再頒布する行為は、原則として著作権法違反、すなわち複製権や翻案権の重大な侵害を構成することになります。
OSSを利用する開発者は、ライセンスで定められた条件を厳格に満たすことによって初めて、適法に著作権を行使する権利を一時的に得ているに過ぎないという点を深く理解しておく必要があります。一般的な商用ソフトウェアの利用規約(EULA)が、主にプログラムを「使用」または「実行」する際の企業とユーザー間の双務的な合意や契約であるのに対し、OSSライセンスは著作権法上の「利用」や「再頒布」に対する権利者からの片務的かつ一方的な許諾という形式をとります。OSSライセンスの利用条件は多岐にわたりますが、大きく分けて二つの潮流が存在します。一つは、著作権の表示やライセンス条文、そして免責条項を維持してソフトウェア内に表示することを求める比較的寛容なライセンスであり、MITライセンスや二条項BSDライセンスなどがこれに該当します。もう一つは、そのコードを含んだ派生物のソースコードの全面的な開示を要求する極めて厳格なライセンスであり、GPL(GNU General Public License)などがその代表格として知られています。
後者のようなソースコード開示義務を持つライセンスは、AI生成コードを利用する企業にとって、後述するように極めて重大なコンプライアンス上の脅威となります。開発の現場でしばしば見受けられる「問題が指摘されたらその時にソースを開示すればよい」という安易な考え方は、権利行使の前に条件を満たしていなければならないという著作権法の基本原則に真っ向から反するものであり、実務上全く許容されません。過去には、GPL違反によって多数の大手テクノロジー企業が提訴され、製品の販売停止命令という致命的な措置に加えて、多額の損害賠償金の支払いを命じられた事例も現実に存在しており、その法的な影響は決して軽視できるものではありません。
2. 生成AIによるコード出力の仕組みとバイラルライセンス感染の脅威
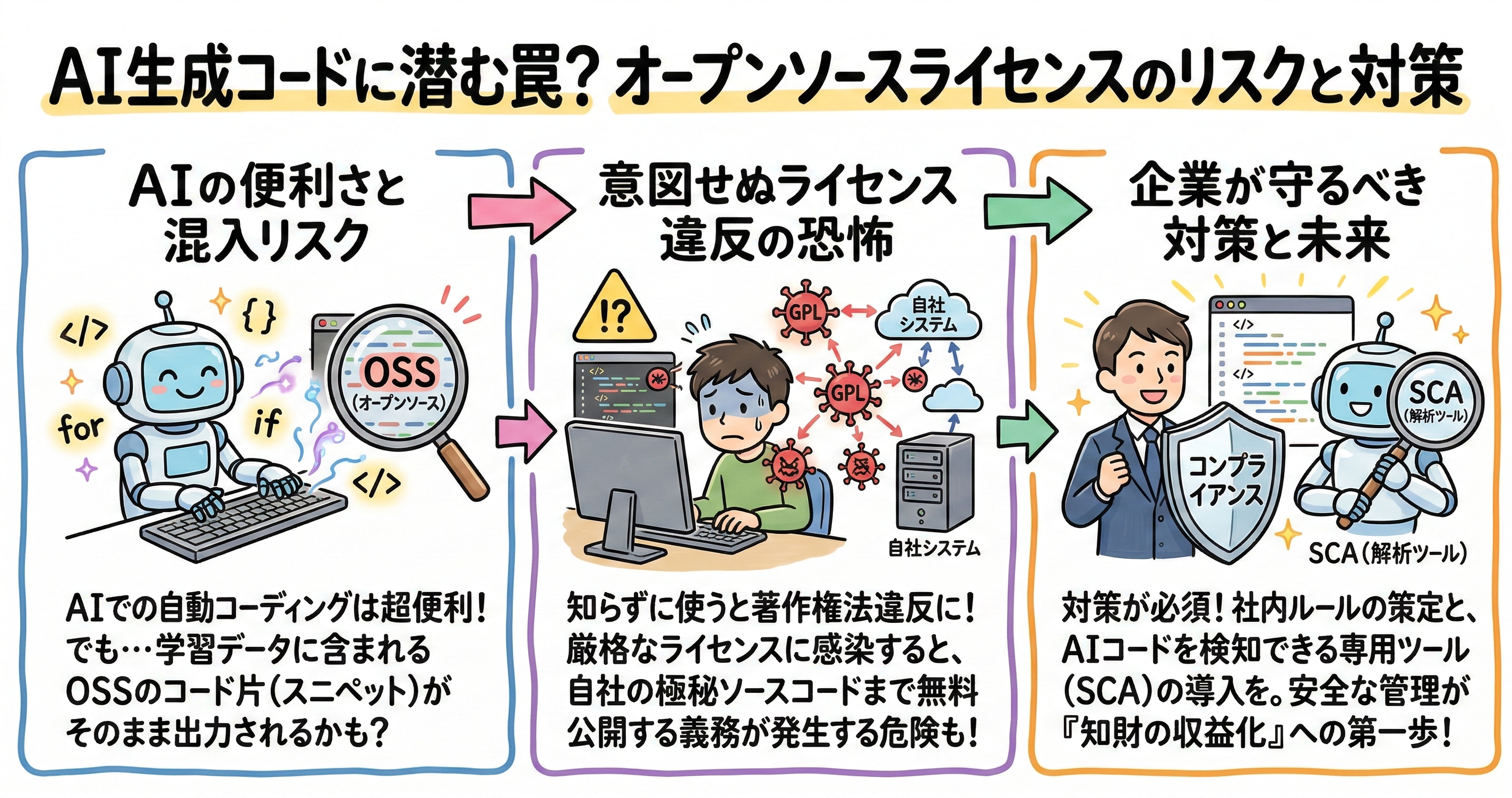
生成AIのコーディングアシスタント機能は、コードの自動補完や定型処理の高速な生成を通じて、ソフトウェア開発のプロセスを劇的に加速させる革新的な技術です。しかし、この圧倒的な利便性の裏側には、深刻な法的リスクと企業コンプライアンス上の重大な課題が潜んでいます。AIモデルの多くは、インターネット上に無数に公開されている膨大なソースコードを学習データの基盤として取り込んでおり、その中には厳格な利用条件を持つオープンソースプロジェクトのコードが多数含まれています。ここで問題の核心となるのは、AIが元の学習データからコードの「断片」、いわゆるスニペットを、そのままの形であるいはわずかに変形しただけでユーザーに出力してしまうという現象です。開発者が便利さに頼ってこれを自社のソースコードにそのまま組み込んだ場合、企業は意図せずして重いオープンソースライセンスの義務を背負うことになります。
特に警戒すべきなのが、先述したGPLバージョン2.0などに代表されるコピーレフト型のライセンスです。GPLのライセンス義務は、GPLライセンスが付与されたプログラム全体をそのまま利用した場合だけでなく、「プログラムの一部」を含む著作物を開発した場合に対しても適用されるという強力な法的拘束力を持っています。コードスニペットは、理論上いかに短い数行のコードであっても、この「プログラムの一部」とみなされる法的なリスクが十分にあります。コピーレフトライセンスがソフトウェア業界でしばしば「バイラル(ウイルス性)」という言葉で形容されるのはまさにこのためです。ほんのわずかなGPLコードの断片が自社の商用アプリケーションに混入しただけで、そのアプリケーション全体がGPLのライセンス義務に「感染」し、多大なコストと時間をかけて開発した独自のプロプライエタリなソースコードまで、無償で一般に公開しなければならなくなるという経営を揺るがす危険性を孕んでいます。
さらに厄介なことに、一般的なAIコーディングツールは、出力したコードがどのような情報源に基づいているか、またどのライセンス体系に縛られているかを明示しないことが大半です。そのため、開発者は出所が全く不明のまま、ライセンス制限のあるコードや著作権で厳重に保護された他者のコードを、悪意なく自社のプロジェクトに統合してしまう恐れがあります。例えば、世界中の開発者が利用するコミュニティサイトであるStack OverflowからAIが学習したコードは、Creative Commons Attribution ShareAlikeという特殊なライセンスの下で提供されており、これらを無断で商用ソフトウェアに利用することも、ライセンス違反のフラグを立てる大きな原因となります。この知財汚染の問題は、企業の合併・買収(M&A)の場面においても絶対に無視できない評価要素となっています。買収対象企業の開発者が、管理者の目を行き届かせることなく生成AIを利用していた場合、コードスニペットレベルでのライセンス汚染がデューデリジェンスにおける致命的な欠陥とみなされ、買収交渉が破談になるケースも増加しています。コンプライアンス違反が発覚した場合の代償は極めて甚大であり、AIによるコードスニペットの混入は、単なる現場の技術的なミスを超えた重大な経営リスクとして認識されなければなりません。
3. GitHub Copilot集団訴訟が浮き彫りにするオープンソース開発者の権利侵害
生成AIとオープンソースライセンスの法的な衝突は、もはや専門家同士の抽象的なリスク論にとどまらず、現実の激しい法廷闘争へと発展しています。その象徴的な事例として、世界中の法務関係者やソフトウェア開発者から固唾を呑んで注視されているのが、プラットフォーマーであるGitHub、親会社のMicrosoft、およびAI開発元のOpenAIに対して提起された「GitHub Copilot集団訴訟」です。GitHub Copilotは、OpenAIの強力な言語モデルを基盤とした非常に優秀なAIコーディング製品ですが、インターネット上の数十億行に及ぶ公開コードを学習データとして徹底的に利用して構築されています。
匿名のプログラマーたちによって構成される原告団の主張の核心は、Copilotがオープンソースプログラマーの多大な労力と善意による成果物を不当に利用し、彼らが明確に設定したオープンソースライセンスの利用条件に明白に違反して莫大な利益を得ているという点にあります。MITライセンス、GPL、Apacheライセンスなど、世界で利用されている代表的な11種類のオープンソースライセンスはすべて、無償での利用を許可する代わりに、原著作者の名前や著作権表示の「帰属」をソースコード内などに明記することを絶対に譲れない必須の条件として定めています。しかし、AIが膨大な学習データから特定のコードを抽出してユーザーに出力する際、これらの重要な帰属情報はシステムによって完全に剥落してしまいます。原告団は、この帰属表示の意図的な欠落が単なる民事上のライセンス違反を構成するだけでなく、デジタルミレニアム著作権法(DMCA)の第1202条が厳しく禁じる「著作権管理情報の違法な削除」に該当し、さらにGitHub自身が定めた利用規約の違反や、開発者のプライバシー権の侵害にもあたると多角的に主張して、大規模な集団訴訟に踏み切りました。
裁判の進行過程において、裁判所はDMCA違反など一部の法的主張については証拠不十分などの理由で棄却の判断を下しましたが、オープンソースライセンスへの違反および契約違反という、開発者の権利保護にとって最も根本的かつ重要な二つの請求については棄却を免れ、現在も詳細な審理が継続しています。この画期的な訴訟がAIを利用するすべての一般企業に示唆する極めて重要なインサイトは、AIツールの提供ベンダーが自社の法的な責任を巧妙に限定しているという事実です。AIベンダー側は、出力されたコードの提案に対して自らは何の知的財産権も主張しないという寛容な態度をとる一方で、その出力結果のプログラムとしての正確性、セキュリティ上の安全性、あるいは他者の著作権侵害の非該当性について、いかなる法的保証も行っていません。つまり、エンドユーザーである企業がAI生成コードを信じて自社製品に組み込み、結果として他社の知的財産権を侵害してしまった場合、その法的な最終責任や損害賠償義務はAIベンダーではなく、利用した企業自身が全額負担しなければならないということです。企業は、AIベンダーの提供するツールを盲目的に信頼するのではなく、自衛のための自己責任において厳格なライセンス管理体制を構築しなければならないという厳しい現実が浮き彫りになっています。
4. 日本の著作権法に基づくAI生成コードの解釈基準と依拠性の問題
AI生成コードに対する法的な評価や判断基準は、各国の法制度や判例によって微妙に異なりますが、日本国内でAIツールを業務利用する企業は、日本の著作権法における独自の解釈基準を正確に把握しておく必要があります。日本の文化庁や著作権に関する関連機関、さらに2025年に公表された米国著作権局の最新の報告書などの見解を総合すると、AIを利用して生成されたプログラムの成果物が他者の著作権侵害にあたるかどうかは、既存の著作物に関する「類似性」と「依拠性」という二つの極めて重要な要件の組み合わせによって判断されます。
第一の要件である類似性とは、生成されたコードの表現形式が既存のオープンソースコードと本質的な特徴において似ているかどうかを問うものです。単なるアルゴリズムのアイデアや機能の概念が共通しているだけでは類似性があるとはみなされませんが、コードの具体的な記述方法や構造が酷似していれば類似性が肯定されます。第二の要件である依拠性とは、既存の著作物を事前に認識し、それを参考あるいはベースにして創作されたかどうかを問うものです。AIモデルが特定のオープンソースリポジトリを学習データとして事前に取り込んでいる場合、そこから出力された同一または極めて類似したコードスニペットを自社製品に利用すると、この類似性と依拠性の双方が強く推認され、著作権侵害となる可能性が極めて高くなります。たとえコードをAIに生成させた現場の開発者自身が、元となった既存のオープンソースプロジェクトの存在を全く知らなかったと弁明したとしても、AIというツールが過去のデータをシステム内に記憶し、それに依存して出力したという事実がある以上、企業として依拠性を否定して法的な責任を完全に免れることは極めて困難です。もし、既存の作品を全く知らず、AIの学習データにも一切含まれていない状態で、全くの偶然により表現が一致してしまった純粋な「偶然の一致」であれば侵害にはなりませんが、インターネット上のあらゆる公開データを学習する現代の巨大なAIにおいて、学習データに含まれていなかったことを悪魔の証明として立証することは現実的ではありません。
また、企業がAIを積極的に活用して新しいソフトウェアを開発する際、「AIが生成したコード自体に、自社の新たな著作権は発生するのか」という点についてもビジネス上非常に重要な法解釈が存在します。現在の日本の著作権法および諸外国の多くの著作権当局の解釈では、人間がAIを単なる便利な道具として使い、プロンプトに一般的な指示を与えたり、AIが自律的に生成したコードをそのまま採用したりするだけでは著作権は認められません。人間の開発者が創作的意図を持ってプロンプトに極めて詳細かつ具体的な指示を与えたり、出力されたコードに対して人間が大幅な修正や論理構造の加筆を行ったりといった「人間の明確な創作的寄与」が客観的に認められない限り、AI生成コード単体には原則として著作権は発生しないとされています。これは、企業がAIを用いて効率的に大量のコードを生成し、巨大なシステムを構築したとしても、そこに人間の関与と知的価値の付加が立証できなければ、そのソフトウェアを自社の独占的な知的財産として法的に保護し、他社へのライセンス供与などの手段で収益化の確固たる基盤に据えることが難しいことを意味しています。自社の知財を守り抜き、ビジネスの武器とするためには、AIの利用履歴を適切に記録・管理し、人間の介在プロセスを明確にしておくことが組織的に求められます。
5. OSIによるオープンソースAIの新たな定義と開発環境の透明性
AI技術の急速かつ不可逆的な進化に伴い、ソフトウェア業界で長年親しまれ、共有されてきた「オープンソース」という言葉の定義自体も、新たな局面を迎えてその根本が揺らぎ始めています。MetaのLlamaモデルやGoogleのGemmaモデルなど、多くの巨大テクノロジー企業が自社の先進的なAIモデルを「オープン」と称して一般の非商用および商用利用に向けて公開していますが、従来のソフトウェアにおけるオープンソースの厳密な基準をそのまま複雑なAIモデルに適用することには大きな無理が生じています。なぜなら、従来のソフトウェアが単なるプログラムコードの論理的な集合体であったのに対し、AIモデルは学習に使われた膨大な「データセット」、アーキテクチャを構成する「ソフトウェアコード」、そして学習の過程で最適化された「パラメータの重み」という、三つの全く異なる要素が複雑に絡み合って初めて機能する高度なシステムだからです。
この「オープンソースAI」という言葉の定義の曖昧さによる業界内の混乱に対処し、開発者に明確な基準をもたらすため、オープンソースの定義を国際的に司る権威ある組織であるOpen Source Initiative(OSI)は、2024年秋に多大な議論を経て「Open Source AI Definition(OSAID)」を策定し、公開しました。OSIの新たな定義によれば、真の意味で「オープンソースAI」と呼べるシステムは、いかなる目的であれシステムを自由に利用する自由、システムの動作を深く研究してコンポーネントを検査する自由、システムをユーザーの任意の目的で自由に変更する自由、そしてシステムを他者と共有する自由という、伝統的な「4つの自由」をAIの領域においてもユーザーに完全に保障するものでなければなりません。
このOSAIDの規定の中で特に注目すべき画期的な点は、「学習データに関する情報の透明性」が極めて厳格に求められていることです。機械学習システムに対してユーザーが独自の有効な変更を加えるためには、学習に使用されたすべてのデータに関する完全な説明をオープンに開示することが必須とされました。これには、データの正確な出所、収集された範囲、データセットの特性、取得方法、データの選択基準、ラベリングの手順、さらにはデータの処理やフィルタリングの仕組みまでが包括的に含まれます。つまり、システムを動かすための要であるデータセットの詳細やパラメータの重みが非公開のままブラックボックスとして隠されているAIモデルは、OSIの厳格な基準に照らし合わせれば真のオープンソースAIとは認められないことになります。
企業が自社の次世代開発基盤として利用するAIモデルを選定する際、この「真のオープンソースAI基準を満たしているか」という視点は極めて重要な意味を持ちます。学習データの詳細が不透明なAIモデルを安易に利用することは、出力結果の中に権利関係が全く不明確な他者のコードや、法的に問題のあるデータ、あるいは倫理的なバイアスが含まれているリスクを、外部から一切検証できないことを意味するからです。OSIによる新たな定義の確立は、業界全体をより倫理的で責任あるAI開発へと向かわせる大きな推進力となるだけでなく、AIを業務で利用する企業に対して、採用するAIモデルのライセンスの安全性と透明性を監査するための、明確な法的指標と行動指針を与えています。
6. 企業に求められるオープンソースライセンス管理とSCAツールの戦略的導入
開発者がウェブブラウザ一つで数百万のオープンソースコンポーネントに瞬時にアクセスし、AIアシスタントから提示されたコードをコピーアンドペーストで簡単に自社のプロダクトに取り込める現代の開発環境において、「権利侵害が外部から指摘されてから事後的にソースコードを開示すればよい」といった甘い対応でライセンス違反を防ぐことは不可能です。権利者の許諾条件を満たさないままコードを利用すれば、その瞬間に著作権侵害が成立し、企業の信用は失墜します。AI生成コードのリスクを効果的に管理し、自社の知的財産を安全な状態に保つために、企業は包括的なコンプライアンス管理体制の構築と、専門的な解析ツールの導入を急務として進める必要があります。
第一に企業に求められるのは、組織的なポリシーの明確な策定と運用です。開発者がAIツールを使用する際の厳格な社内ガイドラインを設け、生成AIの出力結果を企業内で誰がどのように所有・管理するのかの責任の所在を規定すべきです。さらに、万が一著作権侵害が疑われた際に依拠性を法的に否定するための客観的な証拠として、どのような指示やプロンプトでコードを生成したかの詳細な履歴を保存し、特定の著作物を意図的に模倣していないことを証明できるログの永続的な保管体制を整えることが強く推奨されます。
第二に不可欠なのが、高度な専門ツールによる技術的な防御策の徹底です。企業は、自社のソースコードに潜む法的リスクを可視化するためにソフトウェアコンポジション解析(SCA)ツールを活用する必要がありますが、AI時代のツールの選定には細心の注意が必要です。従来の基本的なSCAツールは、パッケージマネージャーの定義ファイルを読み取り、プロジェクト全体としての既知の脆弱性やライセンスを特定することには長けていました。しかし、AIが生成するコードはパッケージというまとまった単位ではなく、テキストの細かな「スニペット」としてソースコードファイル内に直接挿入されます。そのため、パッケージマネージャーに依存する従来のSCAツールでは、AIが密かに持ち込んだライセンス違反のコード片を検知することは事実上不可能です。
このAI特有の極めて困難な課題に対応するためには、スニペットの検出とマッチング機能に特化した次世代のSCAツールの導入が絶対条件となります。市場における代表的なSCAツールの比較として、Black DuckとSnykがよく挙げられます。Snykは開発者中心のアプローチを採用しており、CI/CDパイプラインや各種開発ツールとの統合が容易で、コード作成中の高速な脆弱性スキャンには非常に優れています。しかし、数行単位のオープンソースコードスニペットの出所特定や詳細なライセンス判定という高度な機能においては、必ずしも強みを持っていません。一方で、Black Duckはオープンソースのコンプライアンスとライセンスリスク検出において業界をリードする圧倒的な深さを誇っています。Black Duckはペタバイト級のオープンソースコードと膨大なメタデータを収録した独自の巨大なナレッジベースを保有しており、ソースコードをハッシュ化して部分一致を判定する高度な解析APIを提供しています。これにより、AIが生成したGPLなどのライセンス制限付きコード断片がソースコードファイル内のどこに混在しているかを自動的かつ正確にスキャンし、バージョンやライセンスタイプを的確に特定することが可能となります。企業がAI生成コードを安全に採用する際は、目的に応じて最適なSCAツールを選択し、ライセンス汚染のリスクをソースコードレベルで完全に排除する仕組みを構築することが強く求められます。
7. AIコーディング時代における安全なソフトウェア開発とコンプライアンスの徹底
生成AI技術は、ソフトウェア開発の領域にこれまでにない革新と圧倒的な生産性の向上をもたらしました。しかし、その多大な技術的恩恵を享受し、ビジネスの成長につなげるためには、著作権法と多種多様なオープンソースライセンスに対する深い理解と、日々の開発プロセスにおける厳格なデューデリジェンスの継続が不可欠です。AIが自律的に生成したコードだからといって、それを利用する企業の法的な責任が免除されるわけではありません。むしろ、出所が不透明であり、どのようなライセンスが背後にあるか分からないからこそ、人間が自ら記述したコード以上に慎重なライセンスの確認と管理体制が求められるのです。
企業は、法務部門と開発部門が緊密に連携し、組織的なポリシーの徹底という人的な対策と、最新のスニペット解析ツールの導入という技術的な安全網を敷くという二段構えの対策を講じる必要があります。クリーンなコードベースを維持し、自社が保有する知的財産の権利関係を誰の目にも明確にしておくことこそが、第三者からの予期せぬ訴訟リスクを未然に防ぎ、市場における企業のブランド価値を守るための最良の防御策となります。そして、その健全で強固な知的財産管理の基盤があって初めて、他社への安全なライセンス提供や特許権の売買といった、真の意味での「知財の収益化」を安心して実現することができるのです。ソフトウェア開発におけるAIの活用は今後さらに高度化し、その導入スピードは加速していくことが予想されますが、企業は常に法的コンプライアンスを経営の最優先課題の一つに位置づけ、持続可能で安全な開発環境を構築していくことが強く求められます。
(この記事はAIを用いて作成しています。)
- OSC20251017_OnlineFall URL: https://jpn.nec.com/oss/osslc/doc/OSC20251017_OnlineFall.pdf
- Generative AI coding assistants (ACAs) legal risk URL: https://arxiv.org/abs/2508.16853
- Generative AI tools and AppSec risk URL: https://www.blackduck.com/blog/generative-ai-tools-appsec-risk.html
- Solutions: Artificial intelligence software development URL: https://www.blackduck.com/solutions/artificial-intelligence-software-development.html
- When bots commit AI-generated code to open source projects URL: https://www.redhat.com/en/blog/when-bots-commit-ai-generated-code-open-source-projects
- GitHub Copilot intellectual property litigation URL: https://www.saverilawfirm.com/our-cases/github-copilot-intellectual-property-litigation
- The Copilot Litigation URL: https://www.bakerlaw.com/the-copilot-litigation/
- GitHub Copilot Investigation URL: https://githubcopilotinvestigation.com/
- GitHub Copilot Litigation URL: https://githubcopilotlitigation.com/
- Judge dismisses majority of GitHub Copilot copyright claims URL: https://www.reddit.com/r/programming/comments/1f360xd/judge_dismisses_majority_of_github_copilot/
- GitHub Copilot Investigation URL: https://githubcopilotinvestigation.com/
- 生成AIの包括的まとめと著作権 URL: https://www.leadplus.co.jp/blog/comprehensive-summary-of-generative-ai
- 米国著作権局によるAI生成物の著作権保護に関する報告書 URL: https://www.nagashima.com/publications/publication20250221-2/
- Open Source AI Models: How Open Are They Really? URL: https://www.hunton.com/insights/publications/part-1-open-source-ai-models-how-open-are-they-really
- The Open Source AI Definition URL: https://opensource.org/ai/open-source-ai-definition
- OSI’s 2025 Roadmap to a Stronger Open Source Ecosystem URL: https://opensource.org/blog/your-support-our-focus-the-osis-2025-roadmap-to-a-stronger-open-source-ecosystem
- OSI’s Definition of Open Source AI URL: https://galkinlaw.com/osis-definition-of-open-source-ai/
- Open Source AI Definition and Selected Legal Challenges URL: https://legalblogs.wolterskluwer.com/copyright-blog/open-source-ai-definition-and-selected-legal-challenges/
- How does Black Duck SCA identify open source snippets? URL: https://www.blackduck.com/software-composition-analysis-tools/black-duck-sca.html
- Analyze AI-generated code with Black Duck Snippet API URL: https://www.blackduck.com/blog/analyze-ai-generated-code-black-duck-snippet-api.html
- Snyk vs Black Duck comparison URL: https://www.aikido.dev/blog/snyk-vs-black-duck