標準必須特許(SEP)の特定とFRAND交渉:AIが支える透明性と効率
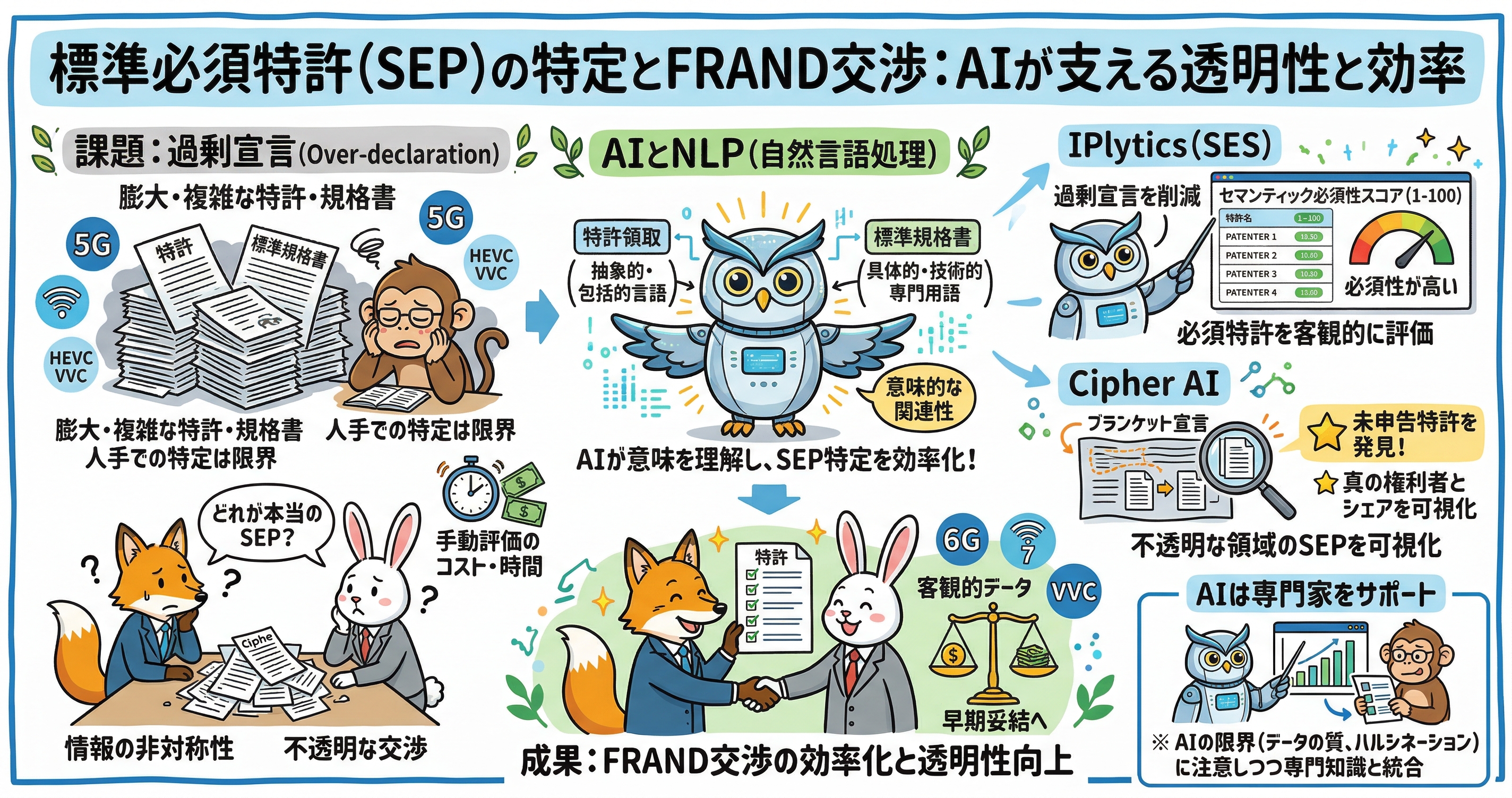
株式会社IPリッチのライセンス担当です。 本日は「標準必須特許(SEP)の特定とFRAND交渉:AIが支える透明性と効率」というテーマについて深く掘り下げて解説いたします。近年、5G通信やWi-Fi 6、さらには次世代の動画圧縮規格であるHEVC/VVCなど、通信および接続技術の高度化に伴い、標準必須特許(SEP)の戦略的な重要性が飛躍的に高まっています。しかしながら、多数の特許クレームと膨大かつ複雑な標準仕様書を人手で比較し、潜在的なSEPを正確に特定する作業はもはや物理的な限界を迎えつつあります。本記事では、自然言語処理(NLP)ベースのAIシステムが特許と標準規格の意味的な関係を理解し、最も重要な特許を迅速に抽出するメカニズムについて解説します。具体的には、LexisNexisの「IPlytics」によるセマンティック必須性スコア(SES)を用いた過剰宣言の削減や、「Cipher AI」によるWi-Fi 6等の未宣言特許の発見手法を取り上げ、AIがいかにしてSEP分析とFRAND交渉を効率化し、市場の透明性を高めるかについて詳しく紐解いていきます。
企業が多額の研究開発投資を行って生み出した技術を単に特許として保護するだけでなく、それを実際の事業利益へと結びつける「知財の収益化」は、現代のグローバル競争において極めて重要な経営戦略です。とりわけSEPは、特定の標準規格を採用する世界中のあらゆる製品に実装されるため、FRAND(公正、合理的、かつ非差別的)条件に基づく適切なライセンス提供を通じて、企業に莫大な収益をもたらすポテンシャルを秘めています。しかし、知財の収益化を成功させるためには、自社および他社の特許ポートフォリオの真の価値を客観的なデータに基づいて正確に把握し、透明性の高い交渉を行うことが不可欠です。弊社が運営する特許売買・ライセンスプラットフォーム「PatentRevenue」では、特許権の売買又はライセンスの希望者に対して、最適なマッチングと戦略的サポートを目的とした無料登録をご案内しております。知財の収益化を目指す皆様は、ぜひこちらのURL( https://patent-revenue.iprich.jp/#licence )よりご登録いただき、次世代の知財戦略にお役立てください。
Patent Value Analyzer | 特許収益化の可能性を無料評価
通信規格の高度化と標準必須特許(SEP)における過剰宣言の課題
現代の産業界において、デバイス間の相互接続性と相互運用性を保証する技術標準は至る所に存在しています。スマートフォンやタブレット端末にとどまらず、自動車のV2X(Vehicle-to-Everything)通信、IoT家電、さらにはスマートシティのインフラに至るまで、数十億台のデバイスがシームレスに通信できるのは、3GPPやETSI、IEEE、ITUといった標準化団体(SSO)が策定する厳格な技術標準があるためです。これらの標準規格を実装する上で回避することができない特許が標準必須特許(SEP)です。SEPを保有する企業は、標準化団体に対して自社の特許をFRAND条件でライセンスする誓約を行います。これにより、規格の実装者は法外なライセンス料を要求されるリスクを回避し、特許権者は技術貢献に対する正当な対価を得ることができます。
しかし、SEPを取り巻く現在のデータ環境には深刻な問題が存在しています。その最大の課題が「過剰宣言(Over-declaration)」とそれに伴う不透明性です。例えば、5G通信の分野だけでも、ETSIなどのデータベースには10万件を超える特許ファミリーが必須である可能性があるとして宣言されています。標準化団体の多くは、特許権者に対して必須となる可能性がある特許を早期に申告することを奨励していますが、標準化団体自身はその特許が本当に標準規格に対して必須であるかどうかを評価・判定することはありません。また、第三者機関による検証メカニズムも存在しないため、宣言された特許の多くは、実際には規格の実装に不要である非必須特許を含んでいます。過去の大規模なサンプリング調査等によれば、4G向けに宣言された特許の必須率は約25%程度であったのに対し、5G向けに至っては約15%程度にまで低下しているとの報告も存在します。
このような過剰宣言の蔓延は、ライセンス交渉において致命的な情報の非対称性を生み出します。実施者(ライセンシー)は、提示された特許群のうちどれが本当に自社の製品に関係しているのかを判断できず、特許権者(ライセンサー)側も自社のポートフォリオの真の価値を客観的に証明することが困難になります。従来、この問題を解決するためには、技術専門家や弁護士が特許のクレームと標準仕様書の該当セクションを1件ずつ手作業で読み込み、詳細なクレームチャートを作成する必要がありました。しかし、数百から数千の特許に対する手動マッピングは、膨大な時間とコストを要します。ある試算によれば、わずか100件の特許の必須性を評価するだけでも、10人の専門家が2週間以上の時間を費やし、15万ドル以上の費用がかかるとされており、ポートフォリオ全体の手動評価はもはや経済的に現実的ではありません。
AIと自然言語処理(NLP)を用いた特許クレームと標準仕様書のセマンティック解析
こうした過剰宣言と手動評価の限界という課題を打破するために登場したのが、人工知能(AI)と高度な自然言語処理(NLP)技術を活用したデータ駆動型のアプローチです。NLPベースのシステムは、特許文書に特有の難解な法的・技術的言語と、標準化団体が発行する膨大かつ複雑な技術仕様書の言語を同時に解析し、両者の間に存在する意味的な関連性を高速に見つけ出すことができます。
特許クレームは通常、特許権の範囲を可能な限り広く確保するために、抽象的かつ包括的な用語を用いて作成されます。一方で、標準仕様書は技術者によって、製品がどのように動作すべきかを厳密に定義するための具体的な専門用語で記述されます。このような言語的性質の違いがあるため、従来の単純なキーワード・マッチング(単語の一致検索)では法的言語とエンジニアリング言語の壁を越えることができず、大量の誤検知を引き起こすか、重要な特許を見落としてしまうという欠点がありました。
最新のAIベースのNLPシステムは、単語の埋め込み(Word Embeddings)やトランスフォーマー(Transformer)ベースの大規模言語モデル(LLM)を活用することで、単なる単語の一致ではなく意味の類似性を深く理解します。例えば、データを送信する装置という特許クレームの抽象的な表現と、基地局からユーザー端末へのダウンリンクシグナリングという標準仕様書の具体的な表現が、技術的に同じ概念を指していることをAIが文脈から学習し、潜在的な必須特許を高い精度で特定するのです。これにより、数千件の特許クレームと分厚い仕様書を同時に分析し、概念的な関係性を理解した上で、詳細な専門家レビューに回すべき必須性の高い特許を自動的にフラグ付けすることが可能となりました。
LexisNexis IPlyticsのセマンティック必須性スコア(SES)による過剰宣言への対策
AIを活用したSEP分析ツールの代表的なプラットフォームとして、LexisNexisが提供する「IPlytics」とその中核機能である「セマンティック必須性スコア(Semantic Essentiality Score: SES)」が挙げられます。IPlyticsは、全世界の特許データと標準化団体の寄書データ、宣言データベースを統合したソリューションであり、このSES機能を通じて過剰宣言問題に直接的な解決策を提示しています。
SESは、独立特許クレームのテキストと、それが宣言された標準仕様書の特定セクションのテキストをAIがセマンティックにマッピングし、その特許が規格に対して必須である可能性を1から100までのスコアで算出する仕組みです。スコアが100に近いほど必須である可能性が極めて高く、逆にスコアが低いものは関連性が薄い、または過剰に宣言されたものであると客観的に推定することができます。
さらに進化したSES 2.0と呼ばれるアルゴリズムでは、高度な深層学習技術が組み込まれており、セルラー通信(2Gから5G)、動画コーデック(AVC、HEVC、VVC)、音声コーデック(AAC、OPUS)、ワイヤレス充電(Qi)、およびWi-Fiといった主要な技術ドメインにおいて、数秒で信頼性の高いスコアを弾き出します。このスコアリングシステムの導入により、特許ポートフォリオマネージャーやライセンス担当者の実務は劇的に変化しました。ライセンサー側は、自社のポートフォリオの中からSESスコアの高い特許を瞬時に抽出し、それらを優先的に外部の専門家に回して精緻なクレームチャートを作成させることで、限られた知財予算を最も強力な特許の証明に集中投資できます。一方でライセンシー側は、相手方から提示された数千件の宣言特許リストをIPlyticsに投入し、SESスコアでフィルタリングをかけることで、リストの大部分が必須性の低い過剰宣言であるという事実をデータで可視化し、FRAND交渉における強力な反論材料とすることができるのです。
Cipher AIを活用したWi-Fi 6やHEVC/VVCにおける未申告特許の発見
過剰宣言とは対照的に、特定の技術分野において深刻な問題となっているのが、宣言漏れや包括的宣言による特許の隠蔽化です。ETSIが管轄するセルラー通信分野では特許番号を特定した宣言が強く推奨されていますが、IEEE(Wi-Fi規格)やITU/ISO/IEC(動画コーデック規格)などの標準化団体では、特許番号を明記せずに「自社が保有する必須特許をFRAND条件で提供する」という包括的な宣言(ブランケット宣言)が広く許容されています。
この結果、Wi-Fi 6やHEVC(H.265)、VVC(H.266)、ワイヤレス充電のQi規格などでは、どの企業がどの特許を保有しているのかが公開データベース上から全く見えないという、極めて不透明な状態が生じています。実装者にとって、誰からライセンス交渉を持ちかけられるか、またロイヤルティの総額がいくらになるかが予測できないことは、製品開発や事業計画において巨大なリスクとなります。
この見えないSEPをAIの力で可視化するのが、LexisNexisが統合した「Cipher AI」の機械学習テクノロジーです。Cipher AIの技術分類アプローチは、特許のテキストと標準仕様を単純に比較するだけでなく、ポジティブ・トレーニングセット(正例)とネガティブ・トレーニングセット(負例)を用いた教師あり学習を特徴としています。
具体的な適用例として、Wi-Fi 6規格における未宣言特許の発見プロセスが挙げられます。まず技術専門家が、特許プールに登録されている検証済みの必須特許などを真陽性とし、Wi-Fiとは無関係の無線特許を真陰性としてデータセットを構築します。約360万件以上の関連特許群の中から、3,000件以上のユニークな特許ファミリーを手動で評価し、FastTextを用いてベクトル化を行った上で二値分類アルゴリズムを訓練した結果、F1スコア0.99という極めて高い精度を達成しました。同様に、次世代動画コーデックであるVVCの分野においても、全世界470万件の特許から専門家が評価したデータを基に機械学習モデルを訓練し、F1スコア0.97という高精度で潜在的な必須特許を特定しています。
これにより、プラットフォームのユーザーは、ブランケット宣言の背後に隠された実際の特許オーナーとそれぞれの市場シェアを正確に把握し、競合ベンチマーキングやライセンス交渉における不確実性を大幅に排除できるようになりました。これまで可視化されていなかった技術領域における「真の権利者」がAIによって白日の下に晒されることで、市場全体の透明性が飛躍的に向上しているのです。
AI駆動のSEP分析がもたらすFRANDライセンス交渉の効率化と未来
標準必須特許のライセンス交渉において、SEP保有者と実施者は、技術的な必須性の証明を主軸とするフェーズと、商業的なFRANDレートの妥当性を議論するフェーズという複雑なプロセスを経ます。このいずれのフェーズにおいても、AIが提供する客観的なデータは交渉の土台として極めて重要な役割を果たします。
実施者側が直面する最大の課題は、特定の規格に関連して合計でいくらのロイヤルティを支払う必要があるのかというロイヤルティ・スタックの問題と、アプローチしてきた特許権者の要求額が全体の中で妥当な割合に基づいているかという市場シェアの算定です。近年、世界的なFRAND訴訟において裁判所が頻繁に採用する算定手法に「トップダウン・アプローチ」があります。これは、対象規格に必須となる特許の全体数(パテント・スタック)を分母とし、特定企業が保有する有効な必須特許数を分子として、適切なロイヤルティ配分を決定する手法です。
AIベースのSEP分析ツールを利用することで、ライセンシーは相手方の要求がSisvelのWi-Fi 6プールなどで設定されている業界水準のレート(例えば端末あたり0.50ドルなど)と比較して過剰ではないか、また経済調査や過去の判例から逸脱していないかをデータに基づいて反証することが可能になります。ライセンサーが「自社は当該技術の特許を10%保有している」と主張した場合でも、IPlyticsのSESスコアで過剰宣言をフィルタリングし、Cipher AIで特定した未宣言特許を含めた真の分母と照らし合わせることで、実際の有効なシェアが遥かに低いことを科学的に立証できる可能性があります。
一方でライセンサー側にとっても、自社ポートフォリオの優位性をAIデータで裏付けることは、透明性の高い誠実な交渉姿勢を示すことにつながります。特にIoTの普及に伴い、自動車メーカーやスマートメーター企業など、これまで通信特許のライセンス交渉に不慣れだった新たな業界がSEPの対象となっています。このような新規参入企業に対して、主観的な主張ではなく、第三者が提供する信頼性の高いAIダッシュボードのデータを開示することは、交渉の円滑化と早期妥結を強く後押しします。
ただし、AI技術の進化がSEPデータ分析を根本から変革しつつある一方で、その限界についても十分に留意する必要があります。AIモデルの性能は入力されるデータの質に完全に依存しており、低品質なデータを学習させれば誤った結果が導き出されるリスクが常に存在します。また、生成AIやNLPの活用においては、ハルシネーション(もっともらしいが事実と異なる出力)のリスクや、特許評価に関する機密情報の取り扱いといった課題も浮上しています。そのため、特許情報のクレンジングや最終的に裁判で証拠として提出される緻密なクレームチャートの作成には、依然として高度な専門知識を持つ技術者や弁護士の介入が不可欠です。AIは専門家を完全に排除するものではなく、無数のノイズの中から価値ある特許の原石を抽出し、専門家が本来注力すべき高度な判断業務を支援するための極めて強力なサポートツールとして位置付けられるべきです。
通信規格が5Gから6Gへ、またWi-Fiが7や8へと進化し続ける中、標準必須特許の対象領域はますます拡大し、複雑化していくことは避けられません。このような時代において、AIがもたらす圧倒的なデータ処理能力と透明性をいち早く自社の知財マネジメントプロセスに組み込み、専門家の深い洞察力とシームレスに統合することができた企業こそが、激化するグローバルな技術競争とSEPライセンス市場において、主導権を握ることができるでしょう。
(この記事はAIを用いて作成しています。)
参考文献リスト
- Bridging the gap Part 1: Insights from SEP declaration data https://www.lexisnexisip.com/resources/bridging-the-gap-part-1-insights-from-sep-declaration-data/
- The Shifting SEP Litigation Landscape https://www.fr.com/insights/thought-leadership/blogs/the-shifting-sep-litigation-landscape-how-changes-in-the-types-of-litigated-seps-can-affect-implementers/
- Closing the SEP Transparency Gap Part 1 https://www.lexisnexisip.com/resources/closing-the-sep-transparency-gap-part-1-how-to-deal-with-data-accuracy-over-declaration-and-blanket-declaration-challenges/
- Part 2: How to Deal with SEP Determination of Large SEP Portfolios https://www.lexisnexisip.com/wp-content/uploads/2023/09/Part-2_How-to-Deal-with-SEP-Determination-of-Large-SEP-Portfolios.pdf
- IPlytics Semantic Essentiality Score https://support.lexisnexisip.com/hc/en-us/articles/41693861499667-Semantic-Essentiality-Score
- Harness AI Patent Tools to Support SEP License Decision Making https://www.lexisnexisip.com/resources/harness-ai-patent-tools-to-support-sep-license-decision-making/
- The Semantic Essentiality Score: Determining Patent Essentiality https://www.lexisnexisip.com/resources/the-semantic-essentiality-score-determining-patent-essentiality/
- LexisNexis IPlytics Platform https://www.lexisnexisip.com/solutions/ip-analytics-and-intelligence/iplytics/
- Who is Leading the Wi-Fi 6 Patent Race 2024 https://ipwatchdog.com/wp-content/uploads/2024/11/Who-is-Leading-the-Wi-Fi-6-Patent-Race-2024.pdf
- Natural Language Processing in Patents: A Survey https://arxiv.org/html/2403.04105v2
- Standard Essential Patents Guide: FRAND, SEPs & Strategy 2025 https://www.patsnap.com/resources/blog/articles/standard-essential-patents-guide-frand-sep-2025/
- Adding to the SEP toolkit: AI and SEP analysis https://www.fr.com/insights/thought-leadership/articles/adding-to-the-sep-toolkit-ai-and-sep-analysis/
- Part 1: How to Deal with SEP Data Accuracy Challenges https://www.lexisnexisip.com/wp-content/uploads/2023/09/Part-1-How-to-Deal-with-SEP-Data-Accuracy-Challenges_Video-Recording.pdf
- Methodology for Unified Patents Wi-Fi 6 OPAL Landscape https://support.unifiedpatents.com/hc/en-us/articles/7250711661847-Methodology-for-Unified-Patents-Wi-Fi-6-OPAL-Landscape
- VVC Landscape Methodology https://support.unifiedpatents.com/hc/en-us/articles/12900363504535-VVC-Landscape-Methodology
- Using AI to Valuate and Determine Essentiality of SEPs https://ipwatchdog.com/2021/06/18/using-ai-valuate-determine-essentiality-seps/
- Navigating SEP Determination Challenges: Quality Claim Charts https://ipwatchdog.com/2024/01/23/navigating-sep-determination-challenges-quality-claim-charts/
- Answering SEP Market Questions Part 3 https://www.youtube.com/watch?v=Y1dNJePtIaA
- Standard Essential Patents Services https://lumenci.com/services/standard-essential-patents/
- Breaking free from data illusions: SEP valuation should not be dominated by formal metrics https://medium.com/@sharon.sheng_16402/breaking-free-from-data-illusions-sep-valuation-should-not-be-dominated-by-formal-metrics-611fd03e3f78