生成AIの利用に伴う著作権侵害メカニズムと「見えない依拠性」
AIライセンス契約におけるベンダーの免責条項の危うさを正確に理解するためには、まず生成AI特有の著作権侵害の構造を法的な観点から把握する必要があります。日本の著作権法第30条の4においては、情報解析などを目的とする場合、原則として著作権者の許可を得ることなく、インターネット上の膨大なデータをAIの学習用データとして利用できるという、世界的に見ても開発者に有利な規定が設けられています。この法整備により、AIモデルの開発フェーズ自体は一定の法的な保護下にあると言えます。さらに、開発段階において他者の著作物を学習に利用したとしても、その著作物に表現された思想や感情を自ら享受する目的がなく、かつ著作権者の利益を不当に害さない限りにおいては、原則として著作権侵害には問われません。
しかし、ビジネスの実務において真に深刻な法的トラブルの火種となるのは、開発フェーズではなく、生成されたコンテンツを事業で「利用」するフェーズです。一般的に、著作権侵害が法的に成立するためには、「類似性(既存の著作物と表現が似ていること)」と「依拠性(既存の著作物を参考にして創作されたこと)」という2つの要件を満たす必要があります。人間のクリエイターによる創作活動であれば、既存の作品の存在を全く知らず、偶然に似た作品を創り出してしまった場合、依拠性が否定されるため著作権侵害にはなりません。
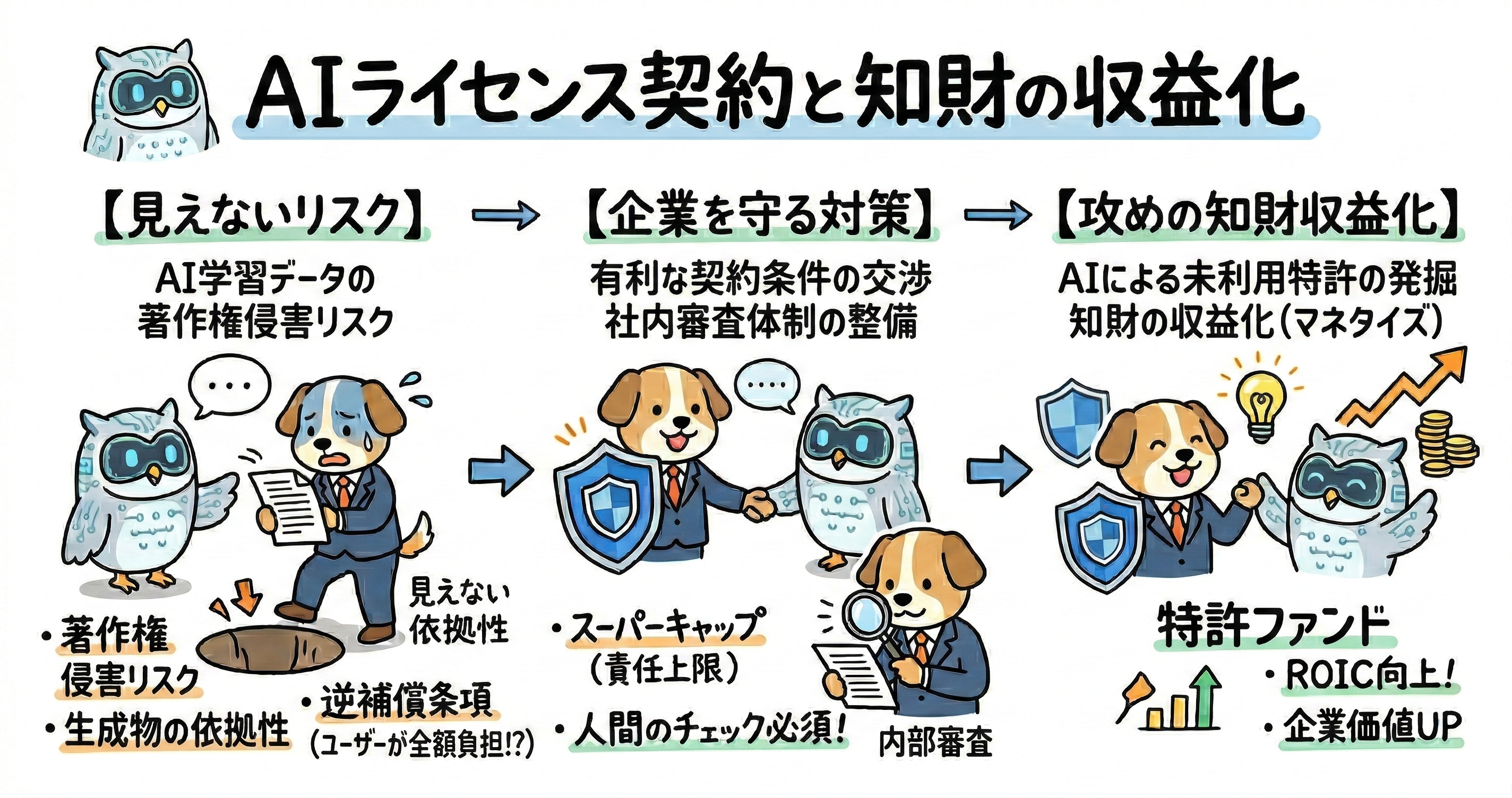
ところが、生成AIを利用する場合、ここに特有の「見えない依拠性」という巨大な落とし穴が存在します。AIを利用する担当者が元ネタとなった著作物の存在を全く知らなかったとしても、AIシステムが過去の事前学習データとしてその著作物を読み込んでおり、その特徴が生成物に色濃く反映されてしまった場合、裁判などの司法判断において「AIシステムを通じた間接的な依拠」が認められるリスクが極めて高いのです。AIの学習データはブラックボックス化されていることが多いため、利用者側が「全くの偶然の一致であり、AIは当該著作物を学習していない」と客観的に証明することは実務上ほぼ不可能です。その結果、この間接的な依拠性による重大な法的責任は、システムを提供したAIベンダーではなく、生成物を自社の事業やプロモーションで利用した企業や担当者自身に直接降りかかることになります。利用者は自らが一切コントロールできない学習データに起因する権利侵害リスクを、知らず知らずのうちに背負わされているというのが、現在の生成AI利用における最大の盲点と言えます。
AIベンダーの利用規約に潜む免責条項と逆補償条項の脅威
こうした構造的な著作権侵害リスクが存在するにもかかわらず、現在市場に流通している多くの生成AIツール(特にSaaS型で提供されるサービス)の標準的な利用規約においては、ベンダー側が徹底して法的責任を回避する仕組みが構築されています。多くの規約には、「AIによって生成された出力物の利用により生じた第三者の権利侵害等の責任はすべてユーザーが負うものとする」旨が明記されています。
従来のBtoB向けソフトウェア・ライセンス契約においては、提供されるソフトウェアそのものが第三者の特許権や著作権を侵害していた場合、ソフトウェア・ベンダーが顧客に代わって訴訟を防御し、発生した損害を賠償する「知的財産権侵害の補償条項」が設けられることが業界の標準的な実務でした。しかし、生成AIの文脈においては、ベンダー側は「AIは汎用的なツールに過ぎず、どのようなプロンプトを入力し、どのような結果を事業に用いるかは顧客の自己責任と判断に委ねられている」という論理を盾にして、この補償義務を頑なに拒否する傾向があります。
さらに企業法務において警戒すべき深刻な事態として、一部のAIベンダーの契約には「逆補償条項(ユーザー側による補償義務)」が巧妙に潜んでいるケースが存在します。これは、ユーザーが入力したプロンプトの内容や、生成物の不適切な利用方法が原因となってAIベンダーが第三者(著作権者など)から訴えられた場合、ユーザーがベンダーの防衛費用(弁護士費用など)や損害賠償額を全額負担しなければならないという条項です。企業が標準的な利用規約をクリックラップ形式で安易に承諾し、業務利用を開始してしまった場合、自社が莫大な損害賠償を被るだけでなく、ベンダー側の法的コストまで肩代わりさせられるという、経営を揺るがしかねない致命的なリスクを抱え込むことになります。
ライセンス契約交渉と責任上限(スーパーキャップ)の設計戦略
このような非対称かつ企業側に著しく不利なリスク構造を是正するためには、エンタープライズ向けのAIライセンス契約交渉において、ベンダーの補償義務と責任上限に関する特約を戦略的かつ緻密に設計することが不可欠です。
一般的なBtoBのクラウドサービスやシステム利用契約では、ベンダーの損害賠償責任の上限を「過去12ヶ月間に顧客が支払った利用料金相当額」に限定する条項が標準的です。しかし、著作権侵害による製品の回収・差止請求や多額の損害賠償、あるいは入力した秘密情報や個人情報の漏えいによる深刻なレピュテーションリスク、さらには集団訴訟の可能性を考慮した場合、月額数万円から数十万円程度の利用料金を上限とするのでは、顧客側のリスクヘッジとして全く機能しません。
そこで契約交渉の切り札となるのが「スーパーキャップ(Super-cap)」という概念の導入です。これは、システムの一時的な停止や軽微なサービスレベルの低下に関する責任については通常の利用料金上限を適用する一方で、「ベンダーのAIモデル(事前学習データを含む)に起因する第三者の知的財産権侵害」や「ベンダーの重大な過失による秘密情報の漏えい」といった、企業経営に致命的な打撃を与えるインシデントに限定して、通常の責任上限を大幅に引き上げた特別な上限額(例えば、数億円規模や契約金額の数十倍)を設定する、あるいは責任上限の例外として青天井(無制限)の賠償責任を負わせるという合意を取り付ける手法です。
もちろん、ベンダー側も「ユーザーが意図的に著作権侵害を引き起こすような不適切なプロンプトを入力した場合まで責任は持てない」と強く反発することが予想されます。この懸念を解消するための現実的な妥協点として、補償義務の範囲を「ベンダーが提供するモデルの基盤技術および事前学習データそのものに起因する侵害」に明確に限定し、「ユーザーが意図的に特定の著作物を模倣させるような指示を行った場合や、ユーザーがアップロードした独自のデータに起因する侵害は補償の対象外とする」という切り分けを契約書面上で行うことが実務的に極めて有効です。
経済産業省ガイドラインに見るデータ保護と開発委託の法務
契約交渉の土台となる国内の法整備や指針についても深く理解しておく必要があります。経済産業省は「AI・データの利用に関する契約ガイドライン」を策定し、データ利活用やAI技術開発に関する契約作成の手引きとして広くビジネスや研究開発の現場に提供しています。このガイドラインは、不正競争防止法の改正による法的枠組みの変化を反映して改訂が重ねられており、実務において非常に重要な羅針盤となります。
特に注目すべきは、2018年の不正競争防止法改正により創設された「限定提供データ」の保護に関する規定です。取引を通じて一定の流通が予定されているデータは、必ずしも同法上の「営業秘密」としての厳格な要件(秘密管理性など)を満たさない場合があり、従来の法律では十分な保護が受けられない懸念がありました。しかし、この改正により、一定の条件下で相手方を特定して提供されるデータが「限定提供データ」として定義され、その不正取得や使用等に対する民事的な保護措置が明確化されました。AIの学習用に他社からデータセットの提供を受ける場合や、自社の独自データを特定のパートナー企業と共有して共同でAIモデルを構築するようなライセンス契約においては、この限定提供データの枠組みを契約に組み込み、データの目的外利用や第三者への漏えいを防ぐ条項を整備することが不可欠です。
また、既存のAIサービスをライセンス利用するだけでなく、自社の業務に特化した独自のAIシステムの開発を外部のベンダーに委託するケースも増えています。この際、システム開発委託契約の形態として「請負契約」とするか「準委任契約」とするかが重要な法的論点となります。生成AIのモデル開発は、事前に出力の精度や挙動を完全に予測することが困難であり、「仕事の完成」を明確に定義することが極めて難しいという性質を持っています。そのため、仕事の完成を目的とし、瑕疵担保責任(契約不適合責任)を伴う請負契約には本質的に馴染みません。生成AIの開発を他社に委託する場合は、専門家の裁量に基づく業務の遂行自体を目的とする「準委任契約」を原則として採用し、開発の各フェーズにおける責任の所在やデータに関する権利帰属を柔軟かつ実態に合わせて配分することが、将来のトラブルを未然に防ぐ鍵となります。
秘密情報の漏えいリスクコントロールと個人情報の取り扱い
著作権侵害のリスクと並んで、AIライセンス契約および利用実務において決して見過ごすことができないのが、顧客がAIに入力したデータ(プロンプトのテキストや添付ファイル)の取り扱いと、秘密情報漏えいのリスクです。業務効率化を図る現場の従業員が、無自覚に顧客の未公開情報、自社のコアとなる技術ノウハウ、あるいは財務データなどをAIシステムに入力してしまうケースが後を絶ちません。もし契約上、入力データの保護に関する取り決めがなされていなければ、これらの機密情報がベンダー側の次世代AIモデルの学習(再学習)データとして吸収され、将来的に全く関係のない他社のAI出力として漏えいする危険性が存在します。
この重大な情報漏えいリスクを契約的に封じ込めるためには、企業がAIツールを選定・導入する初期段階において、入力したデータがベンダーのAI学習に一切使用されない設定、いわゆる「オプトアウト設定」がデフォルトで機能しているか、あるいはエンタープライズ契約の明示的な条項として「ゼロ・データ・リテンション(学習利用の完全排除)」が確約されているかを厳格に審査しなければなりません。
さらに、個人情報保護の観点からも極めて慎重な対応が要求されます。原則として、生成AIのシステムに対して顧客や従業員の個人情報を入力することは、本人の同意取得や利用目的の特定といった個人情報保護法の各種規制に抵触する恐れがあります。それのみならず、学習データセットに個人情報が混入した場合、AIモデルがその個人情報を記憶し、後になって予期せぬ形で第三者に出力してしまうという、深刻なハルシネーション(幻覚)や情報漏えいのトリガーともなり得ます。したがって、ライセンス契約による外部への牽制だけでなく、社内の情報管理規程をアップデートし、AIに入力可能な情報の機密レベル(パブリック情報のみ可、社内限定情報は条件付きで可、極秘・個人情報は入力禁止など)を詳細に定義し、技術的なアクセス制御と契約的な保護の両輪でリスクをコントロールする必要があります。
企業防衛のための強固な内部ガバナンスと人間による介入の徹底
いかに法務部門が交渉を重ねて強固なライセンス契約を締結し、スーパーキャップによる金銭的補償の道筋を確保したとしても、実際に現場で権利侵害や情報漏えいというインシデントが発生してしまえば、企業のブランド価値の失墜や事業継続の危機といった甚大な悪影響を免れることはできません。契約という「法的な盾」はあくまで事後的な救済措置に過ぎず、最も重要なのは、現場の日常的な業務プロセスにおける実践的かつ予防的なリスク回避策、すなわち内部ガバナンスの構築です。
第一の防衛策は、社内における明確な利用ルールおよびガイドラインの策定と運用です。AIを自由に使用してよい業務領域(例えば、一般的なブレインストーミング、社内で完結する議事録の要約、一般的な汎用コードの生成など)と、原則として使用を禁止する、あるいは法務部門の厳格な事前審査を必須とする業務領域(例えば、外部公開用のマーケティングコンテンツの生成、他社製品のデザイン模倣、重要な意思決定に関わる契約書の最終出力など)を明確に区分し、権利侵害が発生し得ない業務フローを確立する必要があります。
第二に、全従業員に対する継続的かつ高度なリテラシー教育の実施です。現場の担当者が、「類似性」や「見えない依拠性」といったAI特有の著作権侵害メカニズムを正しく理解していなければ、悪意なく致命的なリスクを踏み抜いてしまいます。特に危険なのはプロンプト・エンジニアリングにおける禁忌です。特定の既存の作家名、著名なアーティスト名、既存のキャラクター名などをプロンプトに直接入力して「〜風の画像を作成して」「〜の文体で書いて」と指示する行為は、依拠性を自ら意図的に作り出し、補強する行為に他なりません。こうした侵害リスクの高い類似要素を意図的に引き出すようなプロンプトの入力を厳格に禁止し、その理由を社内に周知徹底することが求められます。
第三に、最も確実なリスクフィルターとなるのが、生成されたコンテンツに対する「人間による介入(Human-in-the-loop)」の徹底です。AIの生成物をそのまま最終成果物としてダイレクトに業務利用するのではなく、いかなる場合であっても必ず「初期のたたき台」として扱い、専門知識を持った人間の手によって内容の検証(ファクトチェック)、法的リスクのスクリーニング、および大幅な加筆修正を行うプロセスを業務フローに組み込むことが必須となります。生成AIは、もっともらしい文脈で存在しない特許番号を生成したり、架空の判例を捏造したり、技術的に不正確な実施例を記載したりする「ハルシネーション」を引き起こす可能性を常に内包しています。明細書の作成や技術文書の翻訳などにおいて、このハルシネーションを見逃すことは、権利化の失敗や重大な品質問題に直結するため、人間の専門家による最終確認プロセスを省くことは絶対に避けなければなりません。
最後に、業務で利用するAIツール自体の選定基準の厳格化が挙げられます。従業員が独断で無料のコンシューマー向けAIサービスを業務利用する「シャドーIT」を完全に排除し、企業として公式に導入するツールは、学習データの出所がクリーン(無許諾データや著作権侵害リスクの高いデータを学習プロセスから意図的に排除している等)であることが証明されているものに限るべきです。また、万が一の権利侵害発生時にベンダーが一定の補償を行うことが利用規約上明記されている、エンタープライズグレードのサービスや、法務実務に特化したセキュアなAIツールを選定することが、企業防衛の最前線を構築することに繋がります。
知財戦略との統合:ROICを牽引し企業価値を最大化するAIの活用
強固な契約交渉と社内ガバナンスの構築によってAIのリスクを適切にコントロールできる体制を整えた企業は、次なるステップとして、その強大なAIのデータ処理能力を「知財の収益化」および企業価値の最大化へと振り向ける、攻めのフェーズへと移行すべきです。技術革新が幾指数関数的に進み、グローバル競争が熾烈を極める現代において、有形資産の規模だけで競争優位を保つことは困難になっています。実際、アメリカを代表する大企業群(S&P500)の企業価値の内訳を見ると、実にその9割近くを特許、ブランド、データ、ノウハウといった無形資産が占めるに至っています。自社のコア技術を知的財産として多面的に保護し、それを経営戦略の中核に据えて戦略的に活用することは、もはや選択肢の一つではなく、企業の生存戦略そのものと言えます。
近年、機関投資家や株式市場は、企業の真の稼ぐ力や資本の効率性を測る指標としてROIC(投下資本利益率)を極めて重視しています。このROICの向上において、「知財・無形資産」と「生成AI」の掛け合わせは非常に強力なドライバーとなります。
例えば、従来は人間の知財部員や外部の特許事務所が膨大な時間と多額のコストを費やして手作業で行っていた特許文献の先行技術調査、他社特許の侵害回避を目的としたクリアランス調査、あるいは特許明細書のドラフティングの基礎作業といった業務を考えてみましょう。高度にチューニングされた専用のAIシステムを導入することで、AIは世界中の特許データベースから関連する技術領域の文献を網羅的に抽出し、請求項の類似性や技術的な関連性を瞬時に、かつ客観的に判定することが可能となります。このAIの処理能力は既に人間のそれを大きく上回っており、知財関連業務にかかるコストと時間を劇的に削減します。これは財務的に見れば、ROICの分母である「投下資本」の極めて大きな効率化を意味します。
さらに、AIの力はコスト削減にとどまらず、「売上拡大」すなわちROICの分子である利益の創出にも直結します。自社が保有しているものの、事業化に至っていない膨大な未利用特許群をAIで横断的に分析し、他業界における全く新しい適用可能性や、潜在的なライセンス先の候補企業を自動的に抽出させることが可能になります。これにより、これまで倉庫に眠っていただけの休眠特許を、ライセンス収入を生み出すアクティブな資産へと転換することができます。日本企業や大学には世界トップレベルの特許が多数存在していますが、それが十分に活用されていない「未活用特許」の問題は巨大な機会損失と指摘されてきました。こうした未活用特許を対象として、複数の企業から特許を集約・管理し、ライセンス供与や事業支援を通じて収益化を図る「特許ファンド」の動きも活発化しており、AIはこうしたオープンイノベーションやクロスライセンス交渉の強力な武器となります。得られた莫大な知財収益は、次なる研究開発や新規事業へのイノベーション投資の原資となり、企業内に持続的な成長サイクルを力強く回し始めるのです。
また、資金調達やM&A(企業の合併・買収)の局面においても、AIを活用して緻密に分析・可視化された強固な特許ポートフォリオは、投資家や金融機関に対する技術開発力の最も客観的な証明となります。無形資産価値が明確に示されることで、投資家からの技術評価が劇的に向上し、M&Aにおける適正かつ高い企業価値評価の獲得や、より有利な条件での資本調達に大きく貢献します。さらに、最先端のAIと知財戦略を駆使する革新的な企業文化は、優秀な研究者やエンジニアにとって非常に魅力的に映り、激化する人材獲得競争においても圧倒的に有利に働くという副次的な効果ももたらします。
日本政府が策定した「知的財産推進計画2025」等の国家戦略においても、これからの日本が目指すべき姿として、単なるコストカット型の経済から、知財・無形資産を最大限に活用して成長する「高付加価値型経済」への転換が強く掲げられています。イノベーションを牽引するためには、もはや国内のリソースのみに頼ることは限界に達しており、人材や拠点を含むグローバルな知的資本を日本国内に積極的に誘引し、さらにAIの積極的な活用を大前提とした新たな知的創造サイクルを構築することが国家的な喫緊の課題とされています。企業としても、政府が普及を推進する「知財・無形資産ガバナンスガイドライン」の考え方を深く理解し、コーポレートガバナンスの枠組みの中にAIと知財の戦略的活用を組み込むことが、市場での評価を高める上で不可避となっています。
生成AIという破壊的テクノロジーは、企業に対して「知財の創造と活用の劇的な加速」という前例のない恩恵をもたらす一方で、「間接的な著作権侵害」や「秘密情報漏えい」という、一歩間違えれば致命傷となる制御困難なリスクを同時にもたらす、まさに諸刃の剣です。多くのAIベンダーは利用規約を通じて法的なリスクをユーザー側に巧妙に転嫁しており、企業が契約内容を精査することなく無防備な状態で標準契約を受け入れることは、経営の根幹を揺るがす重大な法的脆弱性を自ら抱え込むことを意味します。
これからの時代の企業法務部門および知財部門に強く求められる役割は、単なる定型的な契約書のレビューや特許出願の事務管理といった受動的な業務プロセスにとどまりません。AIライセンス契約の厳しい交渉の最前線に立ち、ベンダーの免責条項に毅然と立ち向かい、IP侵害に対する補償義務の明確化や、損害の性質に応じたスーパーキャップ(責任上限の大幅な引き上げや別枠設定)、学習データ利用の確実なオプトアウトといった、企業を守るための防衛的条項を戦略的に獲得することが必須の責務となります。
そして、そうした強固な契約的防衛線と、人間による介入の徹底やプロンプト制限を含む厳格な社内ガバナンスによって法的リスクを最小化した上で、その安全なAI基盤をフル活用し、自社の無形資産の価値を最大化していくことこそが、経営を動かす戦略パートナーとしての知財担当者の真骨頂です。AIがもたらす未知の法的リスクを過度に恐れて導入を敬遠するのではなく、高度な法務的知見をもってリスクを精密に切り分け、契約交渉によって適切にコントロールし、知財の収益化という巨大な果実を確実にもぎ取る。この「防御(緻密な法務・契約管理)」と「攻撃(積極的な知財収益化・AI活用)」の高度かつシームレスな統合こそが、激変するグローバルなビジネス環境において日本企業が生き残り、再び飛躍を遂げるための唯一の確実な道筋であると確信しています。
(この記事はAIを用いて作成しています。)
参考文献リスト
LegalOn Technologies, “生成AI 利用規約 比較 著作権 補償”, https://www.legalontech.com/jp/media/copyright-of-generative-ai EMUNI, “知財の収益化 AI 活用 メリット 保護 促進”, https://media.emuniinc.jp/2025/07/23/patent-strategy/ 内閣府, “知的財産推進計画2025”, https://www.kantei.go.jp/jp/singi/titeki2/chitekizaisan2025/pdf/suishinkeikaku.pdf ヨロズ知財戦略コンサルティング, “おわりに――知財担当者が切り拓く未来”, https://yorozuipsc.com/2998325104ai1243427963299921237512383306933600125126300531239831574234502604127861.html 商事法務ポータル (岩田合同法律事務所), “AI・データの利用に関する契約ガイドライン1.1版の解説”, https://portal.shojihomu.jp/archives/37260 ダイヤモンド・オンライン, “知財収益化の仕組み”, https://www.diamondv.jp/article/c6HY96CPTWGkhbEgHMSEi8 経済産業省, “AI・データに関する契約ガイドライン1.1版 解説 PDF”, https://www.meti.go.jp/policy/mono_info_service/connected_industries/sharing_and_utilization/20200619001.pdf 法律事務所ZeLo, “生成AI×著作権の法的論点と最新動向 2025年版”, https://zelojapan.com/seminar/61794 弁護士法人GVA法律事務所 (Kai Law), “生成AI開発で注意すべき法律のポイント”, https://kai-law.jp/web3-legal/law-for-generation-ai/