生成AI時代のデータ規制と知財収益化戦略
1. 国内規制の全体像:生成AI社会実装に向けた「AI事業者ガイドライン」と開発者・利用者の責務
生成AIの技術的ブレイクスルーとそれに伴う社会実装が急激に進む中、日本の行政機関も法整備とガイドラインのアップデートを急ピッチで進めています。2024年4月19日、経済産業省と総務省は共同で、新たな統合的指針である「AI事業者ガイドライン(第1.0版)」を取りまとめ、公表しました。この包括的なガイドラインは、従来の総務省による「AI開発ガイドライン」(2017年)や「AI利活用ガイドライン」(2019年)、および経済産業省による「AI原則実践のためのガバナンスガイドラインVer1.1」(2022年)という3つの既存指針を統合し、生成AIという新たな技術パラダイムに合わせて抜本的にアップデートしたものです。広範なAI関連事業者に対して、統一的かつ分かりやすい行動規範を提供することを目的として、AI戦略会議での「AIに関する暫定的な論点整理」などを経て策定されました。
本ガイドラインの最大の特徴は、AIのエコシステムを構成する事業者を「AI開発者」「AI提供者」「AI利用者」という3つの主体に明確に分類し、それぞれの立場とシステムのライフサイクルに応じたリスク管理手法を詳細に整理している点にあります。特に、基盤モデルや高度なAIシステムを構築する「AI開発者」に対しては、AIモデルの安全性、公平性、そして法的信頼性を担保するための高度なガバナンス体制の構築が強く求められています。具体的には、学習に用いたデータソースの詳細な記録、不適切な個人情報や有害なコンテンツを取り除くための前処理(フィルタリング)の実施、出力におけるバイアス(偏見や差別的表現)を軽減するための技術的対策など、開発プロセス全体のトレーサビリティを確保し、そのプロセスを適切に保存することが推奨されています。
また、同ガイドラインには、企業が具体的なアプローチを自律的に検討できるように設計された実践的なワークシートや、部門横断的な仮想事例に基づくチェックリストが含まれた「別添」資料が用意されており、経営層から開発現場に至るまで全社的なコンプライアンス体制を構築するための実務的な助けとなります。現時点において、このAI事業者ガイドライン自体は直接的な罰則を伴う法的拘束力を持たない、いわゆるソフトロー(非要請的規範)という位置づけです。しかしながら、実務上の観点から見れば、これを遵守しないことは企業の社会的信用の失墜を招くだけでなく、万が一AIによる権利侵害や事故が発生した際における企業の「善管注意義務違反(過失責任)」を問われる強力な根拠となるリスクを孕んでいます。したがって、本ガイドラインは実質的な業界のデファクトスタンダード(事実上の標準)として機能していると認識し、事業活動の前提として組み込む必要があります。
2. 著作権法第30条の4の解釈と限界:文化庁が示す訓練データの合法性チェックと侵害リスク
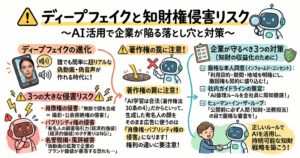
訓練データの合法性をいかに担保するかは、現在のAI開発プロジェクトにおいて最もクリティカルかつ複雑な課題となっています。日本独自の法環境として世界中から注目を集めているのが、著作権法第30条の4という規定です。この条文は、情報解析(機械学習を含む)を目的とする場合、原則として著作権者の許諾を事前に得ることなく、他人の著作物を学習データとして利用できる(権利制限規定)と定めており、日本が「機械学習パラダイス」と呼ばれる所以にもなりました。しかし、技術の急激な進化と権利者からの強い懸念の声を受け、文化庁が2024年3月に公表した「AIと著作権に関する考え方について」の報告書によって、この規定の適用範囲には明確な限界があることが公式に示されました。
同報告書および関連する有識者の見解(例えばジュリスト等の法学専門誌での議論)において最も重要なポイントは、第30条の4のただし書きに規定されている「著作権者の利益を不当に害することとなる場合」の解釈の厳格化です。このただし書きに該当すれば、権利制限の例外は適用されず、原則通り著作権侵害が成立します。具体例として、AIの学習用データとして販売されている市販のデータベースを無断でコピーして学習させる行為や、有料で提供されている記事コンテンツのペイウォール(課金壁)を技術的に回避して網羅的にスクレイピングし学習に利用する場合などが挙げられています。これらは、本来著作権者が得られるはずのデータ販売という市場利益を直接的に代替・簒奪する行為であり、「利益を不当に害する」と判断される可能性が極めて高いと明言されています。
さらに法務実務上、企業が特に警戒すべきなのは、「開発・学習段階」と「生成・利用段階」を法的に厳密に区別して評価するという視点です。近年、企業の業務効率化や社内ナレッジの活用を目的として導入が急速に進んでいる検索拡張生成(RAG:Retrieval-Augmented Generation)という技術があります。RAGにおいて、自社のローカル環境やクラウド上に外部の著作物(ニュース記事や専門書など)を取り込んで専用の検索用データベースを構築する行為は、AIの汎用的な事前学習とは性質が異なります。情報検索と出力を直接の目的とした複製行為とみなされるリスクがあり、第30条の4の対象外となる可能性が指摘されています。
そして「生成・利用段階」において、AIによる出力結果が元の学習データに含まれる著作物と類似性を有している(既存の著作物の表現上の本質的な特徴を直接感得できる)場合、AIがそのデータを学習していたという事実をもって「依拠性」が認められやすくなり、ダイレクトに著作権侵害(複製権や翻案権の侵害)を構成してしまいます。したがって、これからのAI開発やシステム構築においては、インターネット上の不透明なウェブスクレイピングに過度に依存する手法から脱却しなければなりません。権利関係がクリアに証明されたライセンス済みのデータセットを正規のルートで調達し、提供者の利用規約(利用目的の制限や補償条項など)を厳格に遵守する体制へ移行することが、企業防衛の観点から不可避の要請となっています。
3. 個人情報保護法と生成AI:個人データ学習利用へのPPCの注意喚起と匿名化データの課題
著作権問題と並んで、AI開発および利用におけるもう一つの重大な法的リスクとなるのが、個人のプライバシー侵害および個人情報保護法への抵触です。日本国内において生成AIサービスが一般消費者のみならず業務用途で急速に普及した事態を重く見た個人情報保護委員会(PPC)は、2023年6月、AIサービスの提供者およびAIを利用する事業者双方に対して、異例とも言える具体的な注意喚起を行いました。
まず、AI開発・提供者(OpenAI社など)に対する注意喚起では、機械学習のプロセスにおいて、インターネット上から自動収集したデータの中に「要配慮個人情報」が含まれているリスクについて強い懸念が示されました。要配慮個人情報とは、人種、信条、社会的身分、病歴、犯罪の経歴など、本人に対する不当な差別や偏見が生じないように特に厳格な取り扱いを要する情報のことです。これらをあらかじめ本人の同意を得ることなく取得してはならないという個人情報保護法の原則が改めて強調されました。また、機械学習に個人データを利用する場合、利用目的をできる限り特定し、その目的の範囲内でのみ取り扱うよう厳格な規律が求められています。
一方で、AIを業務で利用する一般企業(個人情報取扱事業者や行政機関等)に対する警告も、実務上極めて重要です。従業員が業務効率化のために外部の生成AIサービスを利用し、プロンプト(質問や作業指示文)の入力欄に顧客の個人情報や自社の機密データを入力した場合、重大な法令違反に問われる可能性があります。もし利用しているAIサービスが「入力されたプロンプトデータを自社のAIモデルの将来の学習(再学習)のために利用する仕様」になっていた場合、企業側は本人の事前の同意を得ることなく、AIサービス提供者という「第三者」に対して個人データを提供したとみなされる(個人情報保護法第27条の第三者提供の制限違反)ためです。企業はこのリスクを完全に遮断するために、利用するAIサービスの利用規約やプライバシーポリシーを法務部門が詳細に審査し、データが学習に利用されないオプトアウト設定が確実に行えるエンタープライズ版(法人向け)のAIモデルを契約するなどの技術的・制度的対策を直ちに講じる必要があります。
また、現在進行している個人情報保護委員会の「3年ごと見直し」に係る検討の中間整理(2024年)においては、AI時代の新たなデータ利活用の在り方について踏み込んだ議論が行われています。この中間整理では、厳格な同意規制を見直し、イノベーションと個人の権利保護のバランスを図るための新しい解釈が提示されています。例えば、特定の個人との対応関係が完全に排斥された一般的・汎用的な分析結果や統計の獲得のみを目的としたAI開発など、個人の権利利益の侵害が全く想定されないケースにおいては、例外的に本人同意を不要と整理できるのではないかという方向性が示されました。しかしながら、現代の高度なプロファイリング技術やデータ照合技術を用いれば、一見匿名化されたように見えるデータ群からでも特定の個人を再特定(リ・アイデンティフィケーション)できてしまうリスクが常に存在します。そのため、個人データを利用してAI開発を行う事業者は、単なる法解釈の緩和に甘んじることなく、最新のプライバシー強化技術(PETs)の導入や、厳格なアクセス制御を伴う堅牢なデータガバナンス体制を組織内部に構築・維持し続けなければなりません。
4. 欧州AI規則(EU AI Act)の衝撃:GPAIモデルに対する透明性義務と訓練データ要約の開示
日本国内の法規制だけでなく、生成AIのコンプライアンス戦略を構築する上で「グローバル・スタンダード(国際標準)」として絶対に無視できないのが、欧州連合(EU)が世界に先駆けて施行した包括的なAI規制法「欧州AI規則(EU AI Act)」です。この法律は、AIシステムが社会や個人の基本的人権にもたらすリスクを段階的(許容不能なリスク、ハイリスク、限定的リスク、最小限のリスク)に分類し、リスクの程度に応じて比例的な義務を課すという画期的なアプローチを採用しています。その中でも、世界のAI業界に最も大きな衝撃を与えているのが、生成AIの基盤となる汎用AIモデル(GPAI:General-Purpose AI models)の開発・提供者に対する厳格な透明性義務と知財管理要件です。
EU AI Act第53条では、GPAIのプロバイダーに対して、EUの著作権法を遵守するためのポリシーを社内に策定・実施することに加え、AIモデルの学習に使用したコンテンツに関する「十分に詳細な要約(sufficiently detailed summary)」を作成し、一般に公開することを法的な義務として明確に規定しています。この画期的な要請に応えるため、欧州委員会に新設されたAI Officeは2025年7月、事業者がこの情報開示義務を果たすための「GPAI訓練データ・テンプレート(Training Data Summary Template)」を正式に公表しました。このテンプレートのリリースは、AIガバナンスが単なる倫理的な自主規範から、法的拘束力を伴う義務へと完全に移行したことを示す歴史的なマイルストーンと評価されています。
事業者はこの義務的なテンプレートに従い、AIの訓練に用いられたデータの出所、データセットの性質、データ収集手法(ウェブスクレイピング、ユーザー生成データ、合成データなど)に関する構造化された情報を開示しなければなりません。しかし、ここで規制当局が直面したのは、「著作権者へ情報開示を行うことによる透明性の提供」と「AI開発者の競争力の源泉である営業秘密(トレードシークレット)の保護」という、相反する二つの利益をいかに調整するかという難題でした。結果として欧州委員会は、個々の著作物やファイルを一行ずつ記載するような技術的な詳細リストの公開までは要求せず、データセットの一般的な特性やカテゴリーについてのナラティブ(叙述的)な報告を許容することで、この微妙なバランスを図りました。例えば、商用ライセンスを受けていないサードパーティから取得した非公開のプライベートデータセットについては、一般的な説明のみで要件を満たすことができるよう配慮されています。
さらに、EUにおける法的確実性を高めるための仕組みとして、「GPAI行動規範(Code of Practice)」の導入が進められています。欧州委員会およびAI Boardは、この行動規範の「透明性」および「著作権」に関する章に署名し、そのルールに実質的に準拠する企業は、EU AI Act第53条の義務を満たしていると推定する方針を打ち出しました。これにより、AI開発企業は行政的な手続き負担を軽減しつつ、欧州市場への適法なアクセスを確保することができます。また、透明性を確保するための実務的なツールとして、ユーザーフレンドリーな「モデル・ドキュメンテーション・フォーム」なども提供されています。ただし、オープンソースライセンスの下でリリースされ、モデルのパラメータ構造やウェイト情報が一般に透明に公開されているGPAIモデルについては、システム上の重大なリスクを引き起こす最先端モデル(Systemic Risk)に該当しない限り、これらの厳しい透明性義務の多くが免除されるという特例も設けられており、オープンイノベーションへの配慮もなされています。日本の企業であっても、EU市民のデータを学習に利用する場合や、EU市場にアクセス可能な形でAIサービスを提供する場合には域外適用の対象となる可能性が高く、このEU水準の透明性要求に耐えうるデータ管理体制の構築が急務となっています。
5. 激動のAI法制下における持続可能な知財戦略:ライセンスを通じた知財の収益化と企業の未来
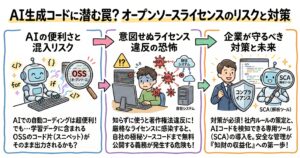
これまで詳述してきたように、日本国内のAI事業者ガイドラインの策定、文化庁による著作権法第30条の4の厳格な限界提示、個人情報保護委員会による法的制裁を視野に入れた注意喚起、そして欧州AI規則(EU AI Act)による強制力を持った透明性義務の導入など、AIの訓練データを取り巻く世界の法環境は、「無断利用(フリーライド)」を一切許容しない方向へと不可逆的に舵を切っています。インターネット上のテキストや画像を無差別にスクレイピングして巨大なモデルを構築するという、AI黎明期にとられていた手法は、今や巨額の損害賠償訴訟リスクや規制当局からの事業停止命令リスクと常に隣り合わせの、極めて危険な行為となりました。事業者は、開発プロセスのあらゆる段階においてデータの出所(プロベナンス)を証明できる証跡を残し、クリーンな環境での開発を徹底しなければなりません。
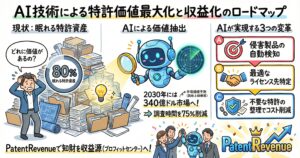
しかしながら、経営戦略や知財戦略の観点から見れば、この強固な法規制の壁とコンプライアンスの厳格化は、全く別のポジティブな意味を持ちます。それは、「適法に権利処理された良質なデータ」および「透明性の高いAI関連技術・特許」の経済的価値が、ビジネスの歴史上かつてないほど高まっているという事実です。企業は、自社の価値あるデータや知的財産を単に社内のサーバーに死蔵させたり、他社による無断スクレイピングの脅威に怯えたりする受け身の姿勢から脱却し、能動的にデータライセンスビジネスや特許のマネタイズへと事業転換すべきパラダイムシフトの只中にいます。
例えば、自社が長年の事業活動を通じて蓄積してきた独自の顧客インサイト、専門的な技術ドキュメント、クローズドな環境で生成されたテキストや画像データなどを、個人情報保護法に抵触しないよう最新の匿名化技術を用いて適切に処理し、著作権法上の権利関係を完全に整理した上で、「安全性が保証されたAI学習用ライセンスデータ」としてパッケージ化すれば、それは世界中のAI開発プラットフォーマーに対する新たな継続的収益源(ストックビジネス)を生み出す強力なエンジンとなります。さらに、EU AI Actが求める厳格な透明性義務に完全対応できるよう、データの出所、収集方法、品質スコアを証明できる「データ・トレーサビリティレポート」を付加価値として提供できれば、市場において極めて有利で高額なライセンス契約を締結することも十分に視野に入ります。
今後のAIエコシステムにおいて、企業の知財部門や法務・コンプライアンス部門に求められる役割は、単に法令違反を防ぐための「ディフェンス(防戦)」だけではありません。自社が保有するデータセットや知的財産の全容を正確に棚卸しし、その市場価値を客観的に算定した上で、外部の専門的なマーケットプレイスなども積極的に活用しながら、安全かつ適法な形で外部へ提供する「オフェンス(知財の収益化)」のエコシステムを構築することです。法規制の趣旨を深く理解し、権利者、AI開発者、そして利用者の三者が適正な利益を享受できる持続可能なデータライセンスの循環を生み出すことこそが、激動する生成AI時代において次世代の企業競争力を決定づける中核的な要素となるでしょう。
(この記事はAIを用いて作成しています。)
- 経済産業省・総務省「AI事業者ガイドライン(第1.0版)」 https://www.meti.go.jp/press/2024/04/20240419004/20240419004.html
- 個人情報保護委員会「生成AIサービスの利用に関する注意喚起等について」 https://www.ppc.go.jp/news/careful_information/230602_AI_utilize_alert
- 個人情報保護委員会「生成AIサービスの利用に関する注意喚起(リーフレット)」 https://www.ppc.go.jp/files/pdf/generativeAI_notice_leaflet2023.pdf
- 情報・システム研究機構(ROIS)SIP第3期 報告書(文化庁AIと著作権に関する考え方解説等) https://ds.rois.ac.jp/wp-content/uploads/2025/05/02-03_%E3%80%90ROIS%E3%80%91SIP%E7%AC%AC3%E6%9C%9F_%E3%83%86%E3%83%BC%E3%83%9E4_ELSI%E5%AE%9F%E5%8B%99%E5%AE%B6%E3%83%81%E3%83%BC%E3%83%A0%E5%A0%B1%E5%91%8A%E6%9B%B8_ver.3.0-6.pdf
- European Commission – AI Act Article 53 https://artificialintelligenceact.eu/article/53/
- European Commission – GPAI Code of Practice https://digital-strategy.ec.europa.eu/en/policies/contents-code-gpai
- William Fry – EU Releases AI Training Data Template https://www.williamfry.com/knowledge/eu-releases-ai-training-data-template/
- Two Birds – Decoding the GPAI Code of Practice https://www.twobirds.com/en/insights/2025/taking-the-eu-ai-act-to-practice-decoding-the-gpai-code-of-practice-and-the-training-data-summary-te
- WilmerHale – European Commission Releases Mandatory Template https://www.wilmerhale.com/en/insights/blogs/wilmerhale-privacy-and-cybersecurity-law/european-commission-releases-mandatory-template-for-public-disclosure-of-ai-training-data