プロンプトが秘密情報を漏らす?生成AI利用時の営業秘密管理と情報漏洩対策
株式会社IPリッチのライセンス担当です。昨今、業務効率化や新規事業創出の起爆剤として、あらゆる業界の企業が生成AIの導入を急速に進めています。しかし、その革新的な利便性の裏側で、経営の根幹を揺るがす深刻なリスクとして浮上しているのが「プロンプト入力による秘密情報の漏洩」です。従業員が日々の業務を効率化しようとする善意から、無意識のうちに社内のコア技術や顧客データ、未公開の事業計画などをAIの入力欄(プロンプト)に打ち込んでしまうと、その情報がAIモデルの学習データとしてサーバーに保存され、意図せず全世界の第三者に出力されてしまう危険性が潜んでいます。特に、従業員が個人アカウントでコンシューマー向けの無料AIツールを業務利用する「シャドーAI」が横行すると、企業の機密は容易に外部へと流出してしまいます。本記事では、生成AI利用時における営業秘密漏洩のリスク構造を紐解き、経済産業省や個人情報保護委員会の最新のガイドラインや法解釈を解説した上で、企業が直ちに講じるべき利用規程の整備やアクセス制御といったシステム的な防衛策について、包括的かつ詳細にお伝えします。
こうした生成AI利用における厳格な情報管理とセキュリティ対策は、単なるIT部門のコンプライアンス業務にとどまらず、企業の「知財の収益化」という極めて重要な経営テーマに直結しています。企業が長年にわたり多大なコストと労力をかけて研究開発し、培ってきた独自の技術ノウハウや顧客基盤は、営業秘密として適切に秘匿・管理されて初めて、市場における強力な競争優位性や他社へのライセンス供与による莫大な収益源となります。しかし、一度でも外部のAIシステム等に無秩序に機密情報が漏洩し、法的な保護要件である「秘密管理性」が失われてしまえば、知財としての財産的価値は一瞬にして棄損し、特許出願の機会はおろか将来のライセンス展開を通じた収益化の道は完全に閉ざされてしまいます。したがって、知財保護の強固な守りと、最新AI技術を活用した攻めのビジネス展開を高度な次元で両立させるためには、法規制とテクノロジーの双方に精通した高度な専門知識とリテラシーを備えた知財人材の存在が組織にとって不可欠です。社内の情報管理体制を盤石なものにし、知財の収益化を力強く牽引する優秀な知財人材を採用したいとお考えの事業者様は、ぜひ「PatentRevenue」で求人情報を無料で登録してご活用ください。詳細につきましては、 https://patent-revenue.iprich.jp/recruite/ をご覧いただき、これからのデジタル競争時代を勝ち抜くための組織づくりにお役立てください。
生成AIの基本的な仕組みとプロンプトを通じた情報漏洩のメカニズム
生成AI、とりわけ大規模言語モデルを用いた文章生成AIは、インターネット上に存在する天文学的な量のテキストデータを事前学習し、言葉と言葉の確率的な結びつきを解析することで、まるで人間が書いたかのように自然で文脈に沿った文章を生成する仕組みを持っています。この技術は、長文の文書要約、多言語間の翻訳、新規プロジェクトの企画書の素案作成、さらにはソフトウェアのソースコード生成やデバッグに至るまで、あらゆる知的業務の生産性を飛躍的に向上させるポテンシャルを秘めています。しかしながら、その事前学習プロセスとクラウドベースでのサービス提供構造そのものに、企業が保有する重要情報の漏洩を引き起こす根本的なメカニズムが内包されていることを正しく理解しなければなりません。
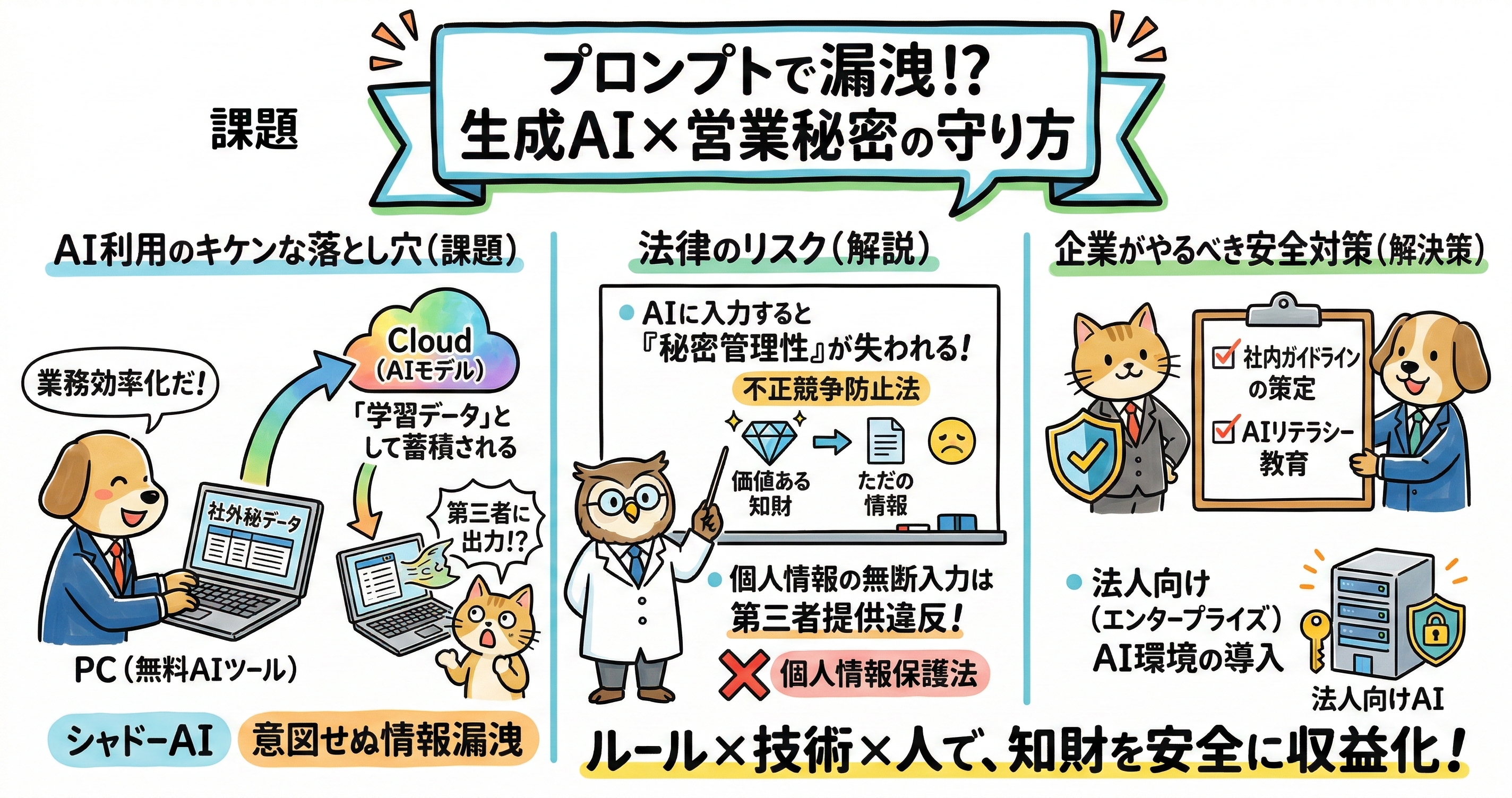
企業が直面する最も警戒すべきセキュリティシナリオは、従業員が業務利用する際に入力する「プロンプト」を通じた、入力データのAIモデルへの学習および外部への流出リスクです。広く一般に向けて無料で提供されているコンシューマー向けの生成AIサービスでは、その利用規約やプライバシーポリシーにおいて、ユーザーが入力したプロンプトの文面やシステムとの対話履歴全体が、AIモデルの精度向上や次世代モデルの再学習のためのデータとしてプロバイダー側に収集・利用されることがデフォルトで規定されているケースが少なくありません。もし従業員が、重要な経営会議の議事録の要約作業や、新製品の極秘プロジェクトに関する企画案の推敲、さらには膨大な顧客リストのデータクレンジングなどの目的で、社内の機密情報をプロンプトとして直接入力してしまった場合、そのデータはAIプロバイダーのクラウドサーバーに暗号化通信で送信された後、モデルを賢くするための巨大な学習データセットの一部として半永久的に吸収されてしまうことになります 。
その結果として引き起こされるのが、意図しない第三者への情報の出力という致命的な事態です。一度AIモデルの神経網(パラメータ)に学習データとして組み込まれてしまった機密情報は、世界中の全く無関係な第三者が入力したプロンプトに対する回答の根拠として、突然出力されてしまう危険性を常に孕むことになります。AIモデルは与えられた文脈(コンテキスト)から最も関連性の高い情報を引き出して回答を生成するため、悪意を持った第三者や競合他社のリサーチャーが、特定の業界用語や製品名などのキーワードを用いて巧みに文脈を誘導するプロンプトを入力する「探索的リクエスト」を行った場合、自社のコア技術の仕様や未公開の戦略情報が、そのまま競合他社のパソコン画面に表示されてしまう事態も想定されます。これは、外部からのハッカーによるサイバー攻撃や不正アクセスによる情報窃取とは異なり、従業員の「目の前の業務を効率化したい」という純粋な善意の行動が引き金となる点で、従来のファイアウォールを中心とした境界防御型のセキュリティ対策では防ぐことが極めて難しい、現代特有のインシデントと言えます 。
不正競争防止法における営業秘密の法的保護と生成AI利用に伴う喪失リスク
企業が自社の競争力の源泉として保有する独自の技術情報や営業情報を法的に保護し、万が一の盗用や産業スパイによる不正な漏洩に対して、裁判所を通じた差止請求や多額の損害賠償請求を行うためには、その情報が単なる社内情報ではなく、不正競争防止法に基づく「営業秘密」として明確に認定される必要があります。我が国の不正競争防止法第2条第6項において、情報が営業秘密として法的に強力に保護されるためには、「秘密として管理されていること(秘密管理性)」、「生産方法、販売方法その他の事業活動に有用な技術上又は営業上の情報であること(有用性)」、そして「公然と知られていないこと(非公知性)」という3つの要件を全て同時に満たさなければならないと厳格に定められています。
生成AIの業務利用が急速に広がる中で、企業の法務担当者や知財部門が最も頭を悩ませているのが、この3要件のうちの要である「秘密管理性」の喪失リスクです。企業が社内ネットワークに多要素認証による厳重なアクセス制限を設け、全従業員や業務委託先との間に網羅的な秘密保持契約(NDA)を結び、重要な電子ファイルには「社外秘」や「Confidential」のウォーターマークを施すなどして、どれほど適切に社内管理体制を構築していたとしても、現場の従業員がその内容をコピーし、学習データのオプトアウト(利用拒否)設定を行わずにコンシューマー向けの生成AIに入力してしまった場合、法的な状況は一変します。その機密情報は、実質的に企業の手を離れ、外部の第三者であるAIプロバイダーの管理下に置かれた状態となります。AIプロバイダー側で学習データとして半永久的に利用される規約に同意した上で情報を送信している以上、もはや自社でコントロールできる秘密状態にはないとみなされ、万が一裁判で争われた場合において「客観的な秘密管理性が維持されていない」と判断され、営業秘密の該当性が否定されてしまうリスクが極めて高くなります。
秘密管理性が否定され、営業秘密としての法的な地位を失うことの経営的代償は計り知れません。もしその後、競合他社が自社の退職者から技術情報を引き抜いたり、あるいは何らかのサイバー攻撃によって情報を不正に取得したりした事実が発覚した場合であっても、その情報が生成AIへの入力によってすでに営業秘密としての要件を欠いていると判断されれば、不正競争防止法に基づく営業秘密侵害罪としての警察への刑事告訴や、民事上での製造・販売の差止請求、および巨額の損害賠償請求を行うための法的根拠が失われてしまいます。自社が莫大な投資を行って生み出した競争力の源泉が、法的に誰もが自由に利用可能な「ただの情報」へと成り下がってしまうのです。
さらに、近年ではリバースエンジニアリング(市場に出回った製品を分解・解析して内部の技術情報を取得する合法的な手法)と、生成AIによる高度な情報解析能力を組み合わせた知財の特定技術も急速に進化しています。仮に自社が特許を出願せず、ブラックボックス化して営業秘密として秘匿していた情報であっても、AIツールを用いて容易に製造プロセスやアルゴリズムの仕組みが解析・推測可能となってしまえば、その情報は「公然と知られていない」という非公知性の要件をも満たさなくなる可能性が専門家から指摘されています。したがって企業は、生成AIという巨大なブラックボックスに対して、どのような機密度レベルの情報を入力してよいのか、自社の情報資産の厳密な棚卸しと区分けを行い、明確なアクセス制御を施すことが、企業の存続を左右する最後の法的防衛線となっています。
経済産業省の営業秘密管理指針の最新改訂と企業に求められる秘密管理体制
こうした社会環境の激変やAIテクノロジーの急激な進化に法制度を適応させるため、経済産業省は令和7年(2025年)3月に、実務のバイブルとも言える「営業秘密管理指針」を全面的に改訂し、公表しました。この指針は、企業が自社の機密情報を不正競争防止法上の「営業秘密」として法的保護を受けるために必要となる、最低限満たすべき水準の管理対策と具体的なアプローチを示した極めて重要なガイドラインです 。
今回の改訂においては、働き方の多様化に伴うテレワークの常態化や雇用の流動化の進行、そしてクラウドサービスの爆発的な普及といった現代のビジネス環境の変化に加え、生成AIという全く新たな技術動向を踏まえた営業秘密管理の考え方が、かつてないほど詳細に整理され追記されました。特に法務・知財関係者の注目を集めたのは、生成AIとの関係における秘密管理性の考え方が初めて公式に明示された点です。従業員が日々の業務効率化を目的として生成AIを利用するケースが企業の大小を問わず常態化する中で、企業は単に「セキュリティが不安だからAIの利用を全面禁止する」という非現実的でイノベーションを阻害する対応をとるべきではありません。むしろ、機密情報の入力に関する明確な社内ルールを策定し、それを全従業員に対して定期的な研修等を通じて周知徹底することが、最低限の秘密管理体制として強く求められています 。
改訂された指針においては、秘密管理措置の対象となる「事業者」の範囲や、正社員だけでなく派遣社員や業務委託先を含む従業員等の定義がより明確化されるとともに、対従業員や対取引先に対する秘密管理措置の具体的な実践手法が拡充されました。生成AIサービスを利用する際の具体的な要件として、入力したデータがAIモデルの学習目的で利用されるか否かを、事前にサービスの利用規約や最新のプライバシーポリシーを読み込んで入念に確認することが推奨されています。そして、もし学習に利用される仕様のサービスを導入するのであれば、営業秘密に該当する極秘情報の入力をシステム的なフィルタリングで制限するか、運用面での厳罰を伴うペナルティを設けて制限することが、法的な秘密管理性を維持するための必須の措置として示唆されています 。
また、同指針では、情報がダークウェブなどの一般的な検索エンジンでは決してアクセスできないアングラサイトに流出した場合の、非公知性の解釈についても新たな見解が示されました。ダークウェブ上に機密情報が公表されたからといって、一般人の目に触れない以上は即座に財産的価値や非公知性が完全に失われるわけではないとする解釈が示された一方で、AIを活用した高度なクローリング技術やダークウェブ監視ツール等によって、その情報が特定のリサーチャー等に広くアクセス可能な状態になれば、実質的に公知とみなされるリスクが高まることも指摘されています。企業は、今回改訂された営業秘密管理指針を法務部門を中心に熟読し、自社の現行の情報管理規程やITセキュリティポリシーが、現在の高度なテクノロジー水準に適合しているかを直ちに見直し、アップデートする必要があります 。
個人情報保護委員会の注意喚起に基づく生成AI利用と第三者提供規制
営業秘密の保護と並んで、企業が生成AIの利用において法的・倫理的に絶対に漏洩を防がなければならないのが、顧客、取引先、そして従業員自身の「個人情報」です。個人情報保護委員会(PPC)は、ChatGPTをはじめとする生成AIの利用が世界規模で爆発的に拡大する中、欧米のデータ保護当局(イタリアのデータ保護当局が一時ChatGPTを使用禁止にするなどの強硬措置をとったことなど)の動向やプライバシー侵害に対する社会的な懸念の高まりを受け、2023年6月に「生成AIサービスの利用に関する注意喚起等について」という公式文書を公表し、国内の個人情報取扱事業者に対して極めて強いトーンで具体的な注意を喚起しました 。
この注意喚起文書の中で、企業の法務担当者やコンプライアンス部門が最も留意すべき重大なポイントは、あらかじめ個人情報の主体である本人の同意を得ることなく、生成AIサービスに個人データを含むプロンプトを入力する行為が、個人情報保護法違反を構成する高い法的リスクを伴うという点です。個人情報取扱事業者が、入力した個人データが、プロンプトに対する単なる応答結果の出力という本来の目的「以外」、すなわちAIプロバイダー側でのLLM(大規模言語モデル)の機械学習や、将来のサービスの精度向上目的で取り扱われることを知りながら、あるいは十分な確認を怠って入力した場合、その行為は個人情報保護法が厳格に禁じている個人データの「第三者提供規制」に真っ向から抵触する可能性が高いと明記されています 。
日本の個人情報保護法では、法令に基づく場合などの一部の例外を除き、原則としてあらかじめ本人の明確な同意を得ないで、氏名や連絡先、購買履歴などの個人データを第三者に提供することを固く禁じています。例えば、カスタマーサポート部門の従業員が、顧客からの長文のクレーム対応メールの文面を生成AIで丁寧な文章に推敲しようとしたり、人事担当者が大量の応募者の履歴書データをAIに入力して面接での質問案を自動作成させたりした場合、そこに個人を特定できる情報が含まれており、かつ利用しているAIツールが無料版などで学習利用を行う仕様であったならば、企業は顧客や応募者の知らぬ間に個人データをAIプロバイダーという「第三者」に無断提供したことになります。これは重大なコンプライアンス違反であり、被害者からの損害賠償請求のみならず、個人情報保護委員会からの行政指導、勧告、最悪の場合は社名公表や罰則の対象となり得る深刻な事態です。
したがって、企業は生成AIを組織的に業務利用するにあたり、導入しようとしているAIサービスが、ユーザーが入力したデータを機械学習のトレーニングに絶対に利用しないことを利用規約やエンタープライズ契約上において明確に約束しているか、あるいはユーザー側でオプトアウト(学習拒否)の設定が確実かつ恒久的に行われているかを厳密に確認する法的義務を負っています。しかしながら、従業員個人のリテラシーに依存したオプトアウト設定では、設定のし忘れやアップデートに伴う設定の初期化、システムの不具合によってデータが学習されてしまうヒューマンエラーのリスクを完全にゼロにすることは不可能です。そのため、原則として個人データを含むプロンプトの入力は、後述する完全に隔離されたエンタープライズ環境を除き、社内規程で固く禁止する運用とすることが、企業にとって最も安全で確実なプライバシー保護対策となります。
企業における生成AI利用ガイドラインの策定と安全な運用体制の構築
これまでに述べてきた法的・セキュリティ的リスクを適切にコントロールしつつ、生成AIがもたらす圧倒的な業務効率化や創造性の向上という多大なメリットを企業活動に享受するためには、全社的な「生成AI利用ガイドライン」の策定と、それを形骸化させずに遵守させるための強固な運用体制の構築が不可欠です。一般社団法人日本ディープラーニング協会(JDLA)は、組織が生成AIを安全かつ円滑に導入・活用するための実践的な指針として、有識者による法的検討を経た「生成AIの利用ガイドライン」のひな形をウェブサイト上で無料公開しており、現在、日本国内の多くの先進的な企業がこのひな形をベースとして自社の業務実態や組織風土に合わせた社内規程を整備しています 。
実効性のある社内ガイドラインに必ず盛り込むべき中核的なルールは、大きく分けて「入力ルール」、「出力結果の利用ルール」、そして「教育と緊急時の運用体制」の三本柱で構成されます。第一の柱である「入力ルール」では、企業が取り扱う情報の機密度に応じた入力制限を厳格に定めます。まず社内の全ての情報を棚卸しし、「一般公開情報(プレスリリースや公開済みのWebサイト情報など)」、「社内関係者外秘(一般的な社内手続きマニュアルなど)」、「極秘(営業秘密、顧客の個人情報、未公開の財務情報、ソースコードなど)」といった形で明確に分類します。その上で、コンシューマー向けのオープンなAIツール(学習利用される可能性のある無料版など)への入力は、一般公開情報のみに限定するといった明確な線引きが必要です。営業秘密や個人情報を含む極秘情報の入力は例外なく禁止とし、違反した場合は懲戒処分の対象となることを就業規則と紐づけて明記することが、抑止力として求められます。
第二の柱である「出力結果の利用ルール」では、生成AIから出力された結果の取り扱いに関する安全基準を定めます。現在の生成AIは、確率的な言葉の結びつきで文章を生成するため、もっともらしい嘘(専門用語で「ハルシネーション」)を堂々と出力する性質が残っています。そのため、AIが出力した情報を事実確認せずにそのまま業務の意思決定や、対外的なIR発表、顧客への回答文に用いることは企業の信用問題に関わる極めて危険な行為です。必ず専門知識を持った業務担当者によるファクトチェック(事実確認)を行うこと、すなわち「Human-in-the-loop(人間の関与)」のプロセスを業務フローに義務付けなければなりません。さらに、生成された文章や、画像生成AIによって作成されたイラストが、インターネット上の第三者の既存の著作物に類似し、結果として著作権侵害を構成する法的リスクも存在するため、出力物をそのまま商用利用したり自社サイトで外部公開したりする際には、知財部門等による事前の類似性スクリーニング体制を構築することが重要です 。
第三の柱は、これらのルールを持続可能なものにするための「教育と運用体制」です。立派なガイドラインを策定して社内ポータルの片隅に掲示するだけでは、セキュリティは機能しません。従業員一人ひとりがその背景にある法的リスクを深く理解し、日常業務の中で意識的に遵守することが重要です。JDLAが推奨するように、「G検定(ジェネラリスト検定)」などの外部資格の取得支援を通じて、AIの基本的な仕組みや関連法規(著作権法、個人情報保護法、不正競争防止法)に関する全社的なリテラシー教育を定期的に実施し、組織全体の底上げを図ることが、結果的に最大のセキュリティ防衛策となります。また、万が一、従業員による機密情報の誤入力や、シャドーAIによる情報漏洩インシデントが発覚した場合の迅速なエスカレーションルート(報告フロー)や、被害を最小限に食い止めるための緊急時対応計画(インシデント・レスポンス・プラン)もあらかじめ詳細に定めておく必要があります。さらに、システム開発を外部のITベンダーに委託して自社専用のAI環境を構築するようなケースにおいては、JDLAが2025年9月に新たに公開した「生成AI開発契約ガイドライン」を参照し、ユーザとベンダ間での秘密情報の取り扱いや、生成物から得られたプロンプトノウハウの権利帰属について、法務的な抜け漏れのない明確な契約を締結することが不可欠です 。
主要AIプロバイダーのデータ利用ポリシーとセキュアなエンタープライズ環境の選定
社内ルールの人的・組織的な整備と並行して、企業は情報漏洩リスクをシステムアーキテクチャのレベルで根本から排除した「エンタープライズ向け生成AI環境」を導入することが強く推奨されます。従業員が日々の業務を効率化したいというプレッシャーから、会社が許可していない無料のAIツールを業務端末や個人のスマートフォンから隠れて使用する「シャドーAI」の状態を放置することは、企業にとっていつ爆発するかわからない最悪のセキュリティホールとなります。安全で統制の取れたAI活用のためには、主要な生成AIプロバイダーが提供する法人向けデータ利用ポリシーを正しく理解し、自社のセキュリティ要件やコンプライアンス基準に適合したセキュアなクラウド環境を選定することが重要です。
まず、業界標準とも言えるChatGPTを提供するOpenAIのサービスは、利用形態によってデータの取り扱い方針が明確に分かれています。個人向けの無料プラン「ChatGPT Free」や有料プラン「ChatGPT Plus」では、ユーザーの会話履歴や入力データがモデルの学習に利用されることがデフォルトで許可されています。学習を拒否するためには、ユーザー自身が設定画面からデータコントロールの項目を開き、都度オプトアウトの設定を手動で行う必要があります。一方、法人向けに設計された「ChatGPT Enterprise」や教育機関向けの「ChatGPT Edu」、および自社システムに組み込むための「APIプラットフォーム」においては、厳格なエンタープライズ向けのプライバシーポリシーが適用されます。これらのビジネスプランでは、顧客のビジネスデータ(入力プロンプト、アップロードしたファイル、および生成結果)はモデルの学習に一切使用されないことが明言されています。また、管理者がワークスペース全体を統制し、いつ誰がどのようなやり取りをしたかの監査ログの取得や、データ保持期間の一元管理が可能であり、SOC 2 Type 2などの国際的なセキュリティ認証も取得しています 。
エンタープライズIT市場で強固な基盤を持つMicrosoftが提供する「Azure OpenAI Service」は、企業が自社のAzureクラウドインフラ内で生成AIを安全に運用するための極めて強力な基盤です。Azure OpenAIに入力されたプロンプトや生成されたコンテンツは、顧客が管理するAzureテナント内に安全に隔離されて保持され、Microsoftが提供する基盤モデルの学習や強化に使用されることは一切ありません。データは不正利用や有害コンテンツの監視目的で最大30日間一時的に保存されますが、顧客の環境内で厳格に暗号化されます。さらにAzureの真骨頂である「On Your Data」機能を利用することで、自社のセキュアなデータベース(Azure AI Searchなど)と連携したRAG(Retrieval-Augmented Generation:検索拡張生成)環境を容易に構築でき、機密データを一切社外に出すことなく、社内規程や独自の技術マニュアルに基づいた精度の高い回答をAIに生成させることが可能です 。
データ検索とクラウド技術の巨人であるGoogle Cloudが展開する「Vertex AI」および業務アプリケーションの「Gemini for Google Workspace」においても、法人向けサービスにおいては「顧客のデータは顧客のもの」という原則が徹底されています。Vertex AIでは、顧客からの事前の許可や明示的な指示がない限り、入力データやカスタマイズしたデータが基盤モデルのトレーニングやファインチューニングに使用されることは絶対にないという「ゼロデータリテンション(Zero Data Retention)」の厳しいポリシーが適用されています。日常業務で用いるGemini for Google Workspaceでも、エンタープライズ版を利用している限り、プロンプトや生成コンテンツが組織外に共有されたり、モデル学習に使用されたりすることはなく、既存のGoogle Workspaceの強固なアクセス権限設定がAIの参照範囲にもそのまま引き継がれます 。
クラウドインフラの世界最大手であるAWSが提供する「Amazon Bedrock」は、Anthropic社のClaudeなど複数の高性能な基盤モデルを用途に応じて選択できるマネージドサービスでありながら、最高レベルのセキュリティとプライバシー保護がアーキテクチャの根底に組み込まれています。Bedrockに入力されたデータはAWSのインフラストラクチャ内で高度に保護され、サードパーティのモデルプロバイダーと共有されることはなく、ベースモデルのトレーニングに使用されることもありません。特にエンタープライズ企業にとって魅力的なのは、AWS KMS(Key Management Service)を使用した顧客管理キーによるデータの暗号化や、AWS PrivateLinkを用いた仮想プライベートクラウド(VPC)からの閉域網接続が標準でサポートされている点です。これにより、データがパブリックなインターネットを一切経由することなく安全にAIモデルにアクセスでき、金融機関や医療機関など極めて機密性の高い営業秘密や個人情報を扱う業界においても、ISO、SOC、HIPAA、GDPR、そして米国政府基準であるFedRAMP High認定といった各種の厳格なコンプライアンス要件を満たしたセキュアな生成AI環境を構築することができます 。
統合的なAIセキュリティ基盤の確立と継続的なガバナンス体制に向けて
営業秘密の確実な保護と生成AIの積極的なビジネス活用という、一見相反する二つの目標を両立するためには、ガイドライン策定やリテラシー教育といった「人的・組織的対策」と、エンタープライズAI環境の導入や厳密なアクセス制御といった「技術的対策」を高度に統合した、全社的なAIガバナンスの確立が不可欠です。
技術的側面では、社内ネットワーク機器やプロキシサーバー、CASB(Cloud Access Security Broker)、DLP(Data Loss Prevention:情報漏洩対策)といった最新のセキュリティソリューションを巧みに組み合わせ、従業員が未許可の外部AIサービスへアクセスすることをネットワークレベルで遮断、あるいは常時監視する仕組みの導入が極めて有効です。これにより、悪意を持った意図的なデータの持ち出しだけでなく、従業員の不注意による機密情報のアップロードを機械的にブロックすることができます。また、社内専用のAIチャットインターフェースを独自に開発し、バックエンドで各ベンダーのAPI(Azure OpenAIやAmazon Bedrockなど)を呼び出す構成にすることで、利用ログの中央集権的な保存・管理や、プロンプト内に個人情報や特定パターンの機密情報(マイナンバーやクレジットカード番号など)が含まれていた場合に自動でマスキングするフィルター処理を組み込むなど、市販のツール以上のより高度で柔軟な統制を実現することが可能になります。
組織的側面では、知財部門、法務部門、情報セキュリティ部門、人事部門、そして実際の業務でAIを活用する事業部門の責任者が横断的に連携した「AI統括コミッティ(委員会)」の常設が強く望まれます。AI技術の進化のスピードは過去のいかなるIT革命と比較しても類を見ないほど速く、数ヶ月単位で新たなモデルや革新的なサービスが次々と登場し、それに伴って関連する著作権法や個人情報保護法などの法的規制、各種ガイドラインも絶えずアップデートされています。一度立派なガイドラインを作成して満足するのではなく、最新の技術動向や国内外の裁判例、法改正の動きを常にモニタリングし、社内規程やシステムの設定をアジャイルに、かつ継続的に見直していく動的なガバナンスのプロセスが組織に求められます。
結論として、生成AIは使い方次第で企業の知財創出スピードを速め、業務効率化を劇的に加速させる強力な武器となりますが、その利用の大前提として、自社のコアコンピタンスである「営業秘密」を絶対に守り抜くという経営トップの強固なセキュリティ意識とシステム基盤が不可欠です。エンタープライズ契約による技術的な安全網をしっかりと敷き、不正競争防止法や個人情報保護法などの法的根拠に基づいた厳格な社内ルールを定着させ、従業員全体のAIリテラシーを高めること。この「技術・ルール・人」の三位一体の対策を経営トップの強力なリーダーシップのもとで愚直に推進することこそが、次世代のデジタル競争環境において知的財産を安全に管理し、中長期的な企業の成長と知財の収益化へと繋げるための唯一にして最短のアプローチとなります。
参考文献リスト:
1 経済産業省 知的財産政策室「営業秘密管理指針」 https://www.meti.go.jp/shingikai/sankoshin/chiteki_zaisan/fusei_kyoso/pdf/027_03_01.pdf
2 個人情報保護委員会「生成AIサービスの利用に関する注意喚起等について」 https://www.ppc.go.jp/news/careful_information/230602_AI_utilize_alert
3 一般社団法人日本ディープラーニング協会(JDLA)「生成AIの利用ガイドライン」「生成AI開発契約ガイドライン」 https://www.jdla.org/document/
4 デロイト トーマツ グループ「Legal Newsletter 2025年8月20日号 営業秘密管理指針の改訂」 https://www.deloitte.com/jp/ja/services/legal/perspectives/legal-newsletter20250820.html
5 OpenAI「Enterprise Privacy」 https://openai.com/enterprise-privacy/
6 Microsoft「Azure OpenAI Service のデータ プライバシーとセキュリティ」 https://learn.microsoft.com/en-us/azure/ai-foundry/responsible-ai/openai/data-privacy?view=foundry-classic
7 Google Cloud「Vertex AI とデータの保持ゼロ」 https://docs.cloud.google.com/vertex-ai/generative-ai/docs/vertex-ai-zero-data-retention
8 Amazon Web Services「Amazon Bedrock のセキュリティ、プライバシー、責任ある AI」 https://aws.amazon.com/bedrock/security-privacy-responsible-ai/
(この記事はAIを用いて作成しています。)