訓練データの出所管理とライセンス確認:リスク低減の手順
株式会社IPリッチのライセンス担当です。本記事では、生成AIの開発において不可欠な「訓練データ」の取り扱いに関する法的なリスク管理と、その実務的な手順について解説します。現在、AIモデルの商用展開においては、著作権法、データ保護法、さらには各プラットフォームの利用規約が複雑に絡み合っており、単一の対策で全てのリスクを回避することは困難です。本レポートでは、日本、欧州、米国における法制度の比較から、データの出所を記録する「プロビナンス」の重要性、さらにはクリエイティブ・コモンズ・ライセンスの解釈に至るまで、専門的な知見に基づき詳述します。開発者が直面する法的不確実性を軽減し、透明性の高いAI開発を実現するための指針を提供することが本記事の目的です。
現代の企業経営において、保有する知的財産をいかに価値に変えるかという「知財の収益化」は、競争力を左右する極めて重要なテーマです。特にAI分野では、高品質で適法に管理された訓練データそのものが、ライセンス提供や技術移転を通じて直接的な収益源となり得る「資産」としての性格を強めています 。このような高度な知財戦略を立案・実行できる人材の確保は、事業成長の鍵を握ります。知財人材を採用したいと考えている事業者様は、ぜひ「PatentRevenue」で求人情報を無料で登録してください。専門性の高い人材とのマッチングを支援するこのプラットフォームは、現在無料でご利用いただけます。詳細な登録は、こちらのURL( https://patent-revenue.iprich.jp/recruite/ )よりお手続きいただけます。
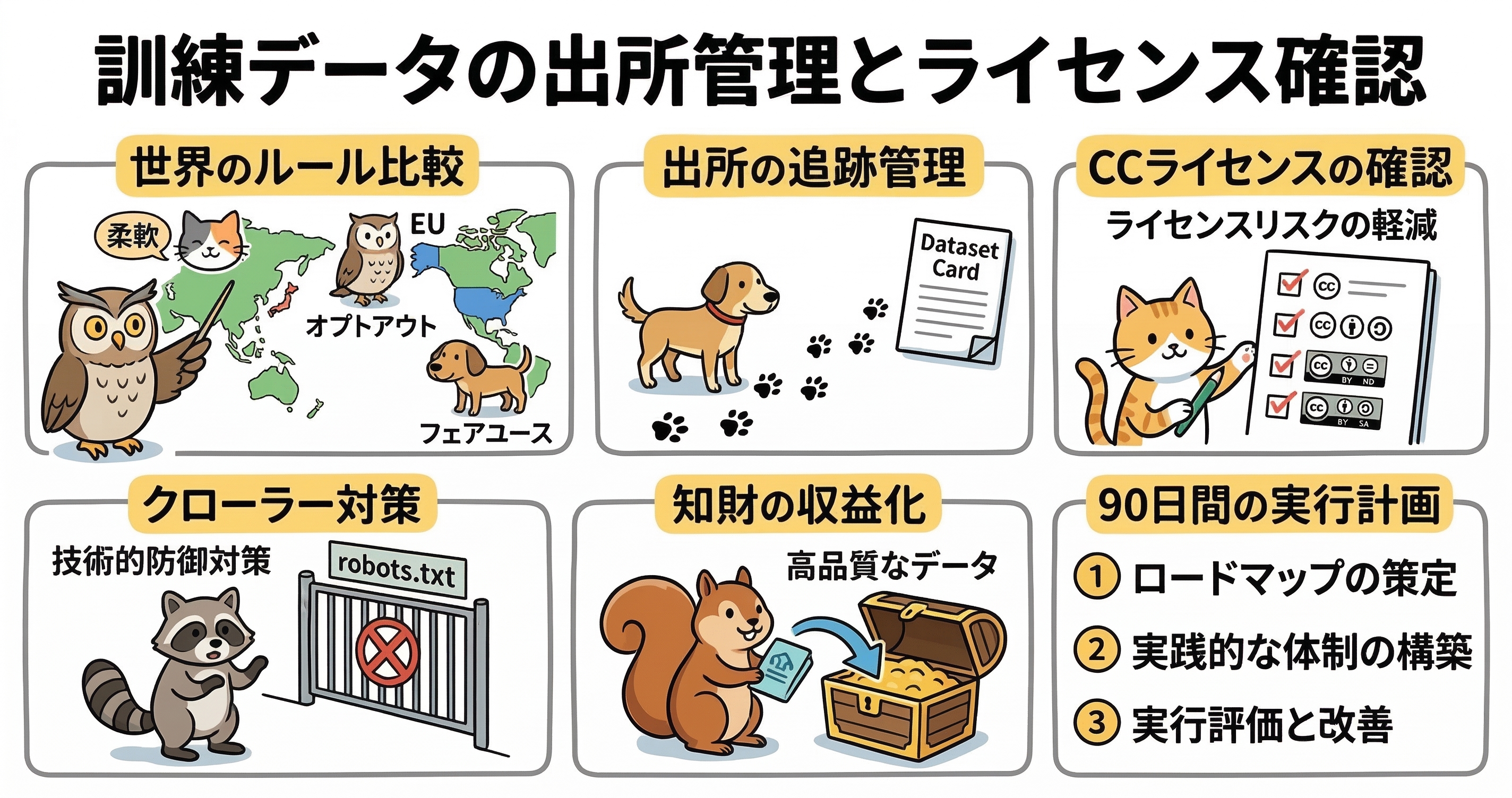
著作権法におけるAI学習の国際的動向と法的解釈
AIモデルの訓練段階における著作物の利用については、国や地域によってその法的許容範囲が大きく異なります。日本の著作権法第30条の4は、世界的に見てもAI開発に対して非常に柔軟な規定であるとされています 。この規定では、原則として「思想又は感情を享受すること」を目的としない利用であれば、著作権者の許諾なく著作物を学習に供することが可能です 。しかし、これは無制限な許可を意味するものではなく、著作権者の利益を不当に害する場合や、情報解析以外の目的が混在する場合には、その適用が制限される可能性があります 。
一方で、欧州連合(EU)においては、デジタル単一市場における著作権指令(CDSM指令)に基づき、より厳格なオプトアウト制度が導入されています 。特に商用目的のテキスト・データマイニング(TDM)に関しては、権利者が「機械判読可能な手段」によって拒否の意思を表示している場合、その著作物を学習から除外しなければなりません 。米国では特定の制限規定ではなく、フェアユース(公正な利用)の法理に基づいて判断されますが、学習に使用されるデータの「変容的利用」の程度や、元の著作物の市場に対する影響が厳しく問われる傾向にあります 。
以下の表は、主要な国・地域におけるAI学習段階の著作権の扱いを比較したものです。
| 項目 | 日本 | EU | 米国 |
| 主要な法的根拠 | 著作権法第30条の4 | CDSM指令第3条・第4条 | フェアユース(17 U.S.C. §107) |
| 商用利用の扱い | 原則として許諾不要(例外あり) | オプトアウトがない限り許諾不要 | 個別の事案ごとに4要素で判断 |
| オプトアウト | 明文規定はないが、利益を害する場合は不可 | 機械判読可能な形式で可能 | 明文規定はないが、市場影響を重視 |
| 透明性の要求 | 学習データの公開検討中 | 学習データの要約公開が必須 | 判例により形成中 |
このように、グローバルな商用モデルを展開する場合、各国の法制度の差異を考慮したリスク管理が求められます 。特に、EU AI法の施行により、EU市場でモデルを提供する事業者は、訓練場所に関わらずこれらのルールを遵守する義務が生じます 。
データプロビナンスの確立と出所管理の技術的手法
データプロビナンス(データの出自管理)とは、データセットがどこから取得され、どのような加工を経て、どのようなライセンスの下で管理されているかを詳細に記録・追跡するプロセスを指します 。AIモデルが生成する出力の責任を問われる場面が増える中、訓練データの透明性を確保することは、法的リスクの低減のみならず、モデルの信頼性や再現性を担保するためにも不可欠なインフラとなっています 。
実務的には、Hugging Faceなどのプラットフォームで採用されている「データセットカード」を用いた管理が普及しています 。これは、データセットの言語、ライセンス、収集手法、考えられるバイアスなどをYAML形式のメタデータとして記述するもので、後続のユーザーや監査者がデータの適合性を即座に判断できるようにする仕組みです 。また、Data Provenance Initiativeのような研究団体は、数千ものデータセットを監査し、そのライセンス状況や元のクリエイターの意図を可視化するツールを提供しています 。
データプロビナンスを確立するための具体的なステップは以下の通りです。
| ステップ | 内容 | 記録すべき項目 |
| 収集(Sourcing) | データの取得元と取得方法の特定 | URL、取得日時、利用規約、robots.txtの状態 |
| 監査(Auditing) | ライセンスの適合性と権利関係の確認 | CCライセンスの種類、商用利用の可否、著作権者の意図 |
| ドキュメント化 | メタデータによる構造化記録 | データセットカード、ハッシュ値、引用情報 |
| 継続的監視 | 権利情報の変更やオプトアウトの追跡 | 最新のオプトアウト信号、権利者からの要求 |
出所の不透明なデータセット(いわゆる「ダークデータ」)を使用することは、著作権侵害のリスクだけでなく、児童性的虐待素材(CSAM)などの違法コンテンツが混入するリスクを孕んでいます 。そのため、商用利用を前提とする場合は、自社で構築したクリーンなデータセット、あるいは信頼できるデータマーケットプレイスから取得した、プロビナンスが明確なデータを使用することが推奨されます 。
クリエイティブ・コモンズ・ライセンスの商用利用におけるリスクと解釈
オープンソースのデータセットの多くは、クリエイティブ・コモンズ(CC)ライセンスが付与されたコンテンツで構成されています。しかし、CCライセンスの条件(BY, NC, ND, SA)をAI学習に適用する際には、その法的解釈に注意が必要です 。CCライセンスは著作権に基づいた許可を与えるものであり、各国の著作権法における制限・例外規定(日本の30条の4など)が適用される場合、ライセンスの条件そのものが法的拘束力を持たないという解釈も存在します 。
しかし、保守的なリスク管理の観点からは、ライセンス条件を尊重することが推奨されます。特に注意すべきは「非営利(NC)」および「改変禁止(ND)」の制約です。
| ライセンス記号 | 名称 | AI学習における解釈とリスク |
| BY | 表示 | 出典の明記が必要。RAGなどの出力時に引用元を表示する手法で対応可能 。 |
| NC | 非営利 | 商用モデルの学習に使用すると、ライセンス違反とみなされるリスクが高い 。 |
| ND | 改変禁止 | 学習過程でのデータの切り出しや形式変換が「改変」とみなされる可能性があり、回避が安全 。 |
| SA | 継承 | 学習後のモデルや生成物が「二次的著作物」とみなされた場合、同一ライセンスの適用を求められる 。 |
特に「非営利(NC)」ライセンスについては、大学などの研究機関が学習させたモデルを、後に営利企業が利用する場合に遡及的なリスクが生じる可能性があります 。また、CCライセンスは著作権のみをカバーしており、プライバシー権や肖像権、データベース権などの他者の権利を免責するものではない点にも留意が必要です 。
クローラーによるデータ収集とEU TDMオプトアウトの遵守
ウェブ上のコンテンツを自動的に収集する「ウェブクローリング」は、AI学習データの主要なソースですが、近年は権利者による拒否(オプトアウト)の動きが加速しています 。特にEU AI法の影響下では、開発者は権利者が表明したオプトアウトを「特定し、遵守する」ためのポリシーを策定しなければなりません 。
現在、オプトアウトを表明する主要な技術的手段には、robots.txt、HTMLメタタグ、HTTPヘッダーなどがあります 。2025年のデータによれば、主要なニュースサイトの約79%が、少なくとも1つのAI学習用ボットをブロックしています 。
| オプトアウト信号の種類 | 対象となるボット(例) | 技術的強制力 | 特徴 |
| robots.txt | GPTBot, ClaudeBot | 任意(紳士協定) | 最も普及しているが、無視されることもある |
| Google-Extended | Googleの学習用ボット | 任意 | 検索インデックスには残しつつ、学習のみを拒否可能 |
| TDMRep | 全般 | 任意 | W3Cが策定した機械判読可能な権利留保プロトコル |
| WAF/CDNブロック | 全般 | 高 | Cloudflare等を用いて、インフラレベルでアクセスを遮断 |
Cloudflareのようなプロバイダーは、ワンクリックで全てのAIクローラーをブロックする機能を提供しており、2024年9月の導入以来、100万以上のドメインがこのオプションを選択しています 。開発者側は、これらの信号を無視してスクレイピングを続行した場合、EU AI法に基づく制裁の対象となるだけでなく、不正アクセス禁止法や利用規約違反による民事訴訟のリスクを負うことになります 。
知財の収益化を支えるデータライセンスと市場価値の向上
適切に管理された訓練データは、AI時代における強力な資産であり、それを活用したビジネスモデルの構築は「知財の収益化」の核心です 。出版社やニュースメディアなどの権利者は、単にAI企業のスクレイピングを拒否するだけでなく、高品質なデータを適正な価格でライセンス提供する「パーミッションベース」の取引へ移行しつつあります 。
例えば、教育系コンテンツのライセンス料は、1ワードあたり0.001ドルから0.01ドルの範囲で取引されることがあり、データの質や独占性の有無によって価格が変動します 。また、IBMやトヨタのような大企業は、自社が保有する特許や技術データをライセンス提供することで、年間数千万ドルから十億ドル規模の収益を上げています 。
知財の価値を最大化し、収益化するための戦略的アプローチは以下の通りです。
- アセットの棚卸しと評価: 自社が保有するデータの種類、権利関係、市場価値を明確にします 。
- AI-Ready化: データをAIが学習しやすい構造に整理し、アノテーション(ラベル付け)を施すことで、単なる情報の集合体から「価値ある訓練データ」へと昇華させます 。
- 多層的なライセンスモデルの構築: 一括販売だけでなく、APIを通じた従量課金、特定の分野に限定した独占的ライセンス、レベニューシェアなど、多様な収益化手法を組み合わせます 。
- 法的保護と技術的保護の併用: 特許やトレードシークレット(営業秘密)としてデータを保護すると同時に、アクセス制御や電子透かしなどの技術的手段で不正利用を防止します 。
データは一度モデルに学習されると、そこから個別のデータを削除することは技術的に極めて困難です 。そのため、収益化のプロセスにおいては、事前の契約交渉と適切な権利管理が将来の価値を守るための生命線となります。
EU AI法における汎用AIモデル提供者の義務とCode of Practice
2024年に成立したEU AI法は、AIモデルの開発者に広範なコンプライアンス義務を課しています 。特に「汎用AI(GPAI)モデル」の提供者は、2025年8月から段階的に適用されるルールに従わなければなりません 。これらの中核となるのが「GPAI Code of Practice(行動規範)」です。
Code of Practiceは、AI法の抽象的な要求事項を実務的なレベルに落とし込んだガイドラインであり、以下の4つの主要な章で構成されています 。
| 章 | 主な義務内容 | 対象となるプロバイダー |
| 透明性(Transparency) | 学習データの要約、技術文書の作成、下流ユーザーへの情報提供 | 全てのGPAIモデル提供者 |
| 著作権(Copyright) | 著作権法遵守ポリシーの策定、オプトアウトの特定・遵守、侵害出力の抑制 | 全てのGPAIモデル提供者 |
| 安全性(Safety) | システム的リスクの評価、レッドチーミング(擬似攻撃テスト)の実施 | システム的リスク($10^{25}$ FLOPs超)を持つモデル提供者 |
| ガバナンス | インシデント報告、内部責任体制の確立、文書の10年間保存 | 全てのGPAIモデル提供者 |
特に著作権に関しては、モデルが著作権を侵害する出力を生成する確率を最小化するための技術的対策を講じることが強く求められています 。これには、学習データから海賊版サイトのコンテンツを排除することや、出力時に既存の著作物との類似性をチェックするフィルタリングの実装が含まれます 。これらの義務に違反した場合、多額の制裁金が科されるだけでなく、モデルの市場からの撤去を命じられる可能性もあります 。
リスク低減に向けた90日間AIガバナンス計画
AI開発における法的・倫理的リスクを管理するためには、単発の調査ではなく、組織的な管理体制の構築が必要です 。中小企業(SME)やスタートアップであっても、投資家や取引先からの信頼を得るためには、構造化されたガバナンス計画の実行が有効です 。
以下に推奨される90日間の導入プランの概要を示します。
- 第1〜30日:監査と現状把握
- 使用している全てのデータセットのリストアップ 。
- 各データの取得元、ライセンス、利用規約の再確認。
- 外部のプロビナンス確認ツール(Spawning AI等)を用いた権利チェック 。
- 第31〜60日:ポリシー策定と体制構築
- 内部的な著作権遵守ポリシーの作成(EU AI法第53条準拠) 。
- データ取得時の承認フローの確立。
- 知財人材の役割分担(データ管理者、ライセンス担当、法務)の明確化。
- 第61〜90日:技術的対策の実装と評価
- オプトアウトを自動検出するパイプラインの実装 。
- 出力時の類似性フィルタリングのテスト。
- 学習データ要約の作成と公開準備 。
このような計画的な取り組みは、AI資産を「負債(法的リスク)」から「資本(収益源)」へと変えるための重要なステップとなります 。
将来的な展望と技術的標準化の重要性
AI学習データの取り扱いに関するルールは現在進行形で形成されており、今後数年間でさらなる標準化が進むと予想されます。欧州委員会は、TDMオプトアウトのための統一的な技術標準を策定するためのコンサルテーションを開始しており、将来的には「公式なオプトアウト・レジストリ(登録所)」が設置される可能性も指摘されています 。
また、技術面では「合成データ(Synthetic Data)」の活用も注目されています。これは、既存の著作物を使用せずにAIによって生成された高品質なデータを学習に用いる手法であり、著作権リスクを根本から回避する手段として期待されています 。しかし、合成データのみでの学習はモデルの劣化(モデル崩壊)を招く恐れもあり、依然として「現実世界の高品質なデータ」への需要は高く維持されるでしょう。
結論として、AI開発におけるリスク低減の鍵は、徹底した出所管理(プロビナンス)と、変化し続ける国際的な法規制への迅速な適応にあります。開発者は、法務、技術、そして知財戦略を統合したアプローチを採ることで、法的安全性を確保しつつ、イノベーションを加速させることが可能となります。高品質なデータセットの構築と適法な管理は、将来的な「知財の収益化」を実現するための最も確実な投資であると言えます。
(この記事はAIを用いて作成しています。)
参考文献
- AI学習データの著作権比較(2024-2025), https://yorozuipsc.com/uploads/1/3/2/5/132566344/3f8dfbf99bf9bd25d0a4.pdf
- Data Provenance Initiative FAQ, https://www.dataprovenance.org/faq
- Data Provenance Initiative About, https://www.dataprovenance.org/about
- Data Foundation: Data Provenance in AI, https://datafoundation.org/news/reports/697/697-Data-Provenance-in-AI
- arXiv: Generative AI and Data Collection Practices, https://arxiv.org/html/2512.21775v1
- Network Law Review: Generative AI and Fair Use, https://www.networklawreview.org/mahari-longpre-generative-ai/
- Creative Commons: Using CC-Licensed Works for AI Training, https://creativecommons.org/using-cc-licensed-works-for-ai-training-2/
- Shuji Sado’s Blog: Tracing CC Licenses across AI, https://shujisado.org/2026/02/16/tracing-creative-commons-licenses-across-ai-training-data-models-outputs/
- LSE Impact Blog: CC Licenses and Academic Work for AI, https://blogs.lse.ac.uk/impactofsocialsciences/2025/11/24/creative-commons-licenses-and-copyright-may-not-stop-academic-work-being-used-to-train-ai/
- University of Aberdeen: CC Licenses and GenAI, https://www.abdn.ac.uk/library/blog/creative-commons-licenses-and-genai/
- open-access.network: Data and CC Licenses for AI, https://open-access.network/en/blog/data-and-creative-commons-licenses-training-material-for-artificial-intelligence
- European Parliament: EU Copyright and AI Training, https://www.europarl.europa.eu/RegData/etudes/ATAG/2025/769585/EPRS_ATA(2025)769585_EN.pdf
- AI-AT EU: AI Copyright Primer, https://ai-at.eu/wp-content/uploads/2026/03/AICopyright_INPUT_Primer_v1_final.pdf
- Taylor & Francis: TDM Exceptions in the EU, https://www.tandfonline.com/doi/full/10.1080/17579961.2024.2392928
- CMS Law-Now: Interplay of AI and Copyright Law, https://cms-lawnow.com/en/ealerts/2025/01/interplay-of-ai-and-copyright-law-how-do-the-options-proposed-in-the-uk-s-recent-consultation-compare-with-the-eu-s-general-tdm-exception
- Traple Konarski Podrecki: AI Training and Opt-out Mechanisms, https://www.traple.pl/en/trenowanie-ai-i-mechanizmy-opt-out-dla-uprawnionych-z-tytulu-praw-autorskich-w-ue-wciaz-wiecej-pytan-niz-odpowiedzi/
- Patent Release: AIを活用した特許活用術, https://patentrelease.com/ai%E3%82%92%E6%B4%BB%E7%94%A8%E3%81%97%E3%81%9F%E7%89%B9%E8%A8%B1%E6%B4%BB%E7%94%A8%E8%A1%93%EF%BC%9A%E6%96%B0%E3%81%97%E3%81%84%E6%8A%80%E8%A1%93%E3%81%A8%E6%B3%95%E5%BE%8B%E3%81%AE%E8%AA%BF%E5%92%8C/
- Las Vegas Sun: Veritone Transforms AI Supply Chain, https://lasvegassun.com/news/2026/mar/10/veritone-transforms-the-ai-supply-chain-with-the-l/
- Evelyn Learning: AI Training Data Dilemma for Publishers, https://evelynlearning.com/blog/the-ai-training-data-dilemma-how-educational-publishers-are-navigating-copyright-fair-use-and-content-licensing-in-the-age-of-machine-learning
- Blank Rome: Data Analytics and AI Licensing, https://www.blankrome.com/services-and-industries/healthcare-litigation/data-data-analytics-and-ai-licensing-litigation-and
- JD Supra: AI as IP TM Framework Guide, https://www.jdsupra.com/legalnews/ai-as-ip-tm-framework-a-practical-guide-7741041/
- Thales Group: Monetizing AI, https://cpl.thalesgroup.com/software-monetization/monetizing-ai
- Ocean Tomo: AI as Intellectual Property, https://oceantomo.com/insights/ai-as-intellectual-property-a-strategic-framework-for-the-legal-profession/
- Monaca Press: Hugging Face Data Cards, https://press.monaca.io/atsushi/18126
- 文化庁: AIと著作権に関する考え方(案)概要, https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/pdf/94037901_01.pdf
- Innoventier: AIと著作権の基本的な考え方, https://innoventier.com/archives/2023/07/15231
- Playwire: How to Block AI Bots with robots.txt, https://www.playwire.com/blog/how-to-block-ai-bots-with-robotstxt-the-complete-publishers-guide
- Secure Privacy: Consent Management for AI Training Data, https://secureprivacy.ai/blog/consent-management-for-ai-training-data
- Wikipedia: Robots.txt, https://en.wikipedia.org/wiki/Robots.txt
- SoftwareSeni: How to Govern AI Crawler Access, https://www.softwareseni.com/how-to-govern-ai-crawler-access-to-your-website-in-2026/
- BuzzStream: Publishers Block AI Study, https://www.buzzstream.com/blog/publishers-block-ai-study/
- Spawning AI API, https://api.spawning.ai/spawning-api
- GitHub: Spawning DataDiligence, https://github.com/Spawning-Inc/datadiligence
- IPTC: Generative AI Opt-Out Best Practices, https://iptc.org/std/guidelines/data-mining-opt-out/IPTC-Generative-AI-Opt-Out-Best-Practices.pdf
- Cloudflare Press: Changing AI Crawling Enforcement, https://www.cloudflare.com/press/press-releases/2025/cloudflare-just-changed-how-ai-crawlers-scrape-the-internet-at-large/
- Clifford Chance: Copyright Compliance under EU AI Act, https://www.cliffordchance.com/insights/resources/blogs/ip-insights/2025/10/copyright-compliance-under-the-eu-ai-act-for-gpai-model-providers.html
- EU AI Act: Code of Practice Overview, https://artificialintelligenceact.eu/code-of-practice-overview/
- Stibbe: EU’s GPAI Code of Practice, https://www.stibbe.com/publications-and-insights/eus-gpai-code-of-practice-the-worlds-first-guidance-for-general-purpose
- EU AI Act: Introduction to Code of Practice, https://artificialintelligenceact.eu/introduction-to-code-of-practice/
- EU AI Act: High-level Summary, https://artificialintelligenceact.eu/high-level-summary/